
Bamboo is coming
Regularization 정규화 본문
Regularization 정규화
- normalization과 regularization는 모두 오버피팅을 방지하는 공통 목표가 있다. 그러나 두 기법의 차이점은 normalization은 입력 데이터의 범위를 일정하게 조정하는 반면, regularization은 모델의 복잡도를 제한하여 학습 과정에서 과적합을 방지하는 방법을 사용한다는 것이다.
- Normalization: 입력 데이터의 범위가 다를 경우, 이를 일정한 범위로 조정하여 학습을 돕는다. 이로 인해 모델이 학습을 더 쉽게 하고, 빠르게 수렴할 수 있게 된다.
- Regularization: 모델의 복잡도가 너무 높으면 오버피팅이 발생할 수 있다. 규제화는 모델의 복잡도를 제한하여 이를 방지한다. 가장 흔한 방법은 가중치의 크기를 제한하는 L1 규제화와 L2 규제화가 있다.
- Regularization은 오버피팅 방지 뿐만 아니라, local minima 탈출에도 효과가 있다.
도함수(derivative)가 0이 된 local minima 순간에도 추가된 정규항때문에 가중치는 업데이트를 지속한다.
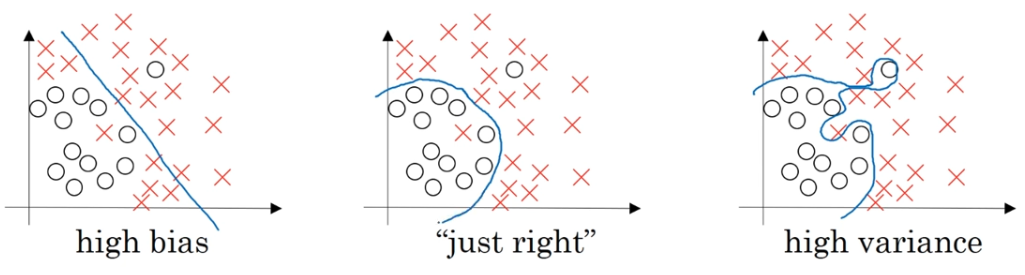
정규화에 따른 bias and variance
https://2ndyoung.tistory.com/74
bias and variance/underfitting and overfitting
bias: 모델을 통해 얻은 예측값과 실제 정답과의 차이 평균 예측값이 실제 정답값과 얼마나 떨어져 있는 지를 나타냄 Variance: 다양한 데이터 셋에 대해 예측값이 얼마나 변할 수 있는 지에 대한 Qua
2ndyoung.tistory.com
1. Norm
- Norm: 벡터의 크기, 벡터의 길이
- norm은 regularization의 기초가 되는 개념이다.
- 가중치 행렬이 너무 커지는 것을 방지하기 위한 추가 항을 넣어 정규화를 진행시킴. 이를 프로베니우스 노름이라고 하는데 람다를 크게 해서 가중치 행렬을 0에 가깝게 만들 수 있다.
- 다양한 층을 저장하고 있긴 하지만 로지스틱 회귀와 비슷해짐

2. L1 regularization
2.1. L1 norm
$\| x\|_1= \sum_{i=1}^n=x_i $
- L1 Norm: 절댓값의 합
- 예) 벡터 x = [3, -4, 2]에 대한 L1 노름은
||x|| = |3| + |-4|+ |2| = 9 - 2차원 평면에서 격자점 사이의 거리는 manhattan distance(=taxicab geometry)로 불린다.
- 두 점 A(1,2)와 B(4,6) 사이의 Manhattan distance
= $|x_2-x_1|+|y_2-y_1|$
=∣4−1∣+∣6−2∣ = 7
-> 어느 방향으로 가든 총 7블럭 이동. 항상 동일하게 이동한다.
2.2 L1 Loss
$\sum_{i=1}^n|Y_{true}-y_{pred}|$
- 정답과 예측값의 거리를 L1 norm 방식으로 계산
2.3. L1 regularization
2.3.1 수식
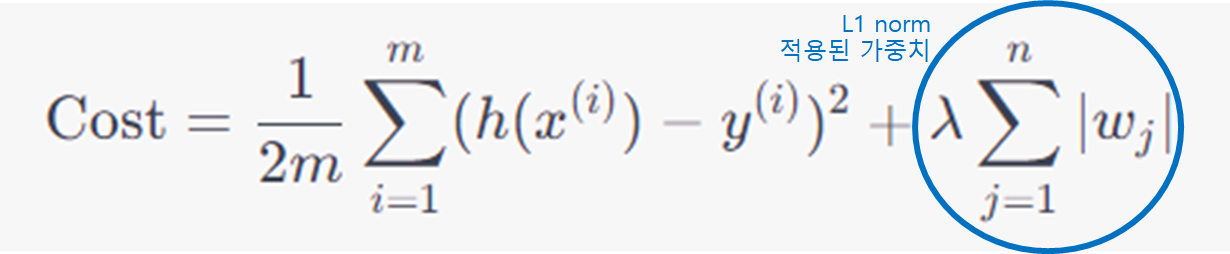
- $$hh(x^{(i)})$$는 예측값
- $y^{(i)}$는 실제값
- $w_j$는 가중치
- $\lambda$는 정규화 강도를 제어하는 하이퍼파라미터
- $n$은 특성의 수, 모델의 가중치 개수
- $m$은 샘플의 수
1.2.2 특징
- L1 regularization은 Lasso Regression에 주로 사용된다.
2. L2 regularization
- L2 Norm: 원점의 거리


regularization의 효과는 더 간단한 네트워크를 만듬.
과대적합에 도움이 됨.
분산의 감소를 결과로 만듬
Ridge Regression
tan

활성화함수가 선형인 구간을 찾아야 함.
비용함수가
정규화 매개변수(람다)가 매우 크면 매개변수 w는 매우 작다.
$g(z) = tanh(z)$일 때, 람다가 커지면 w는 작아진다.
w가 작아지면 상대적으로 z도 작아진다. 표시된 빨간 부분에서 z가 상대적으로 작은 값을 갖게 되면 g(z)는 거의선형 함수가 된다.
따라서 모든 레이어는 거의 선형회귀처럼 직선을 가지게 된다.
강의 1에서 나오듯이 모든 층이 선형이면 전체 네트워크도 선형이다. 따라서 선형 활성화함수를 가진 깊은 네트워크에 경우에도 선형 함수만을 계산하게 된다.
-> 매우 복잡한 과대적합된 데이터세트까지 맞추기 어려움
$z=wa+b$일 때, 선형을 찾기 위해서는 z가 거의
L1 정규화 (L1 Regularization)
Lasso Regression
수식: 손실 함수에
$\lambda\sum^n_{j=1}|w_j|$
∣ 항을 추가합니다.
특징:
특성 선택: 불필요한 특성의 가중치가 정확히 0이 됩니다. 중요한 특성만 선택됩니다.
절대값 페널티: 가중치의 절댓값을 패널티로 사용합니다.
미분 불가능한 점: 절댓값 함수는 0에서 미분이 불가능하므로, 최적화가 더 복잡할 수 있습니다.
희소한 해: 특성 중 일부만 선택되므로, 가중치 벡터가 희소해집니다.
L2 정규화 (L2 Regularization)
수식: 손실 함수에
$\lambda\sum^n_{j=1}|w^2_j|$
항을 추가합니다.
특징:
가중치 축소: 모든 가중치가 0에 가깝게 만들지만, 정확히 0이 되지는 않습니다.
제곱 페널티: 가중치의 제곱을 패널티로 사용합니다.
미분 가능: L2 정규화 항은 모든 지점에서 미분 가능하므로, 최적화가 더 간단합니다.
비희소한 해: 모든 특성이 어느 정도 사용되므로, 가중치 벡터가 비희소해집니다.
정리: L1 vs L2
특성 선택: L1은 특성 선택의 효과가 있으나, L2는 그렇지 않습니다.
패널티 형태: L1은 절댓값, L2는 제곱을 패널티로 사용합니다.
해의 희소성: L1은 희소한 해를, L2는 비희소한 해를 만듭니다.
미분 가능성: L1은 미분 불가능한 점이 있으나, L2는 모든 지점에서 미분 가능합니다.
두 정규화 방법은 서로 보완적인 특성을 가지고 있으므로, 때로는 둘을 함께 사용하는 Elastic Net과 같은 방법도 활용됩니다. 선택하는 정규화 방법은 문제의 특성과 요구 사항에 따라 달라질 수 있습니다.
3. Dropout regularization
신경망의 각각의 층에 대해 노드를 삭제하는 확률 설정하는 것.
삭제된 노드는 들어가는 링크와 나가는 링크를 모두 삭제
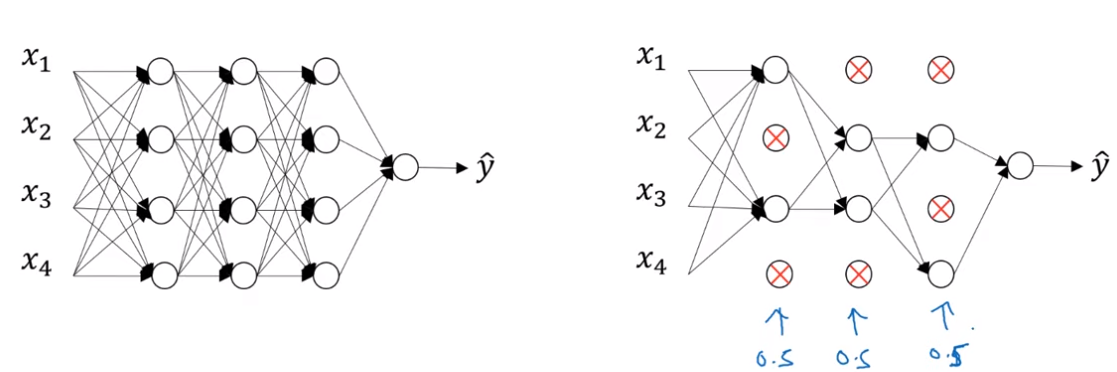
더 작고 간소화된 네트워크를 사용해 학습을 시킴.
각각의 샘플에서 더 작은 네트워크를 훈련시키는 방법
구현 방법
1. implementing dropout(Inverted dropout)
랜덤값에 따라서 bool 벡터를 사용해서 값을 탈락시켜주고
input의 값에 다시 보존확률을 나눠서 계산해줌.
경사하강법의 하나의 반복마다 0의 위치가 달라지기때문에 네트워크가 새로운 네트워크를 하는 것이 됨.
test에서는 드롭아웃 사용하지 않음. -> 결과가 균일해야되고 테스트에 드롭아웃을 시키면 노이즈만 심해짐.
서로 다른 유닛을 반복해 평균을 낼 수 있지만 비효율적이고 그냥 테스트 값과 비슷하게 나옴.
드롭아웃이 작
4. Data augmentation
수평 방향으로 뒤집은 이미지를 훈련에 추가시켜 훈련세트를 늘리는 방법, m개의 독립적인 샘플을 얻는 것보다 중복 샘플이 많아져서 좋지는 않음. 그 외에도 회전시키고 확대시켜서 이미지의 무작위적인 왜곡과 변형을 통해 가짜 훈련 샘플을 얻을 수 있음. 이런 추가적인 가짜 이미지들은 완전히 새로운 독립적인 고양이 샘플을 얻는 것보다 더 많은 정보를 추가해주지는 않지만 컴퓨터적인 비용이 들지않고 계산할 수 있음 데이터를 더 얻을 수 있는 값싼 방법
데이터 증가는 정규화 기법과 비슷하게 사용될 수 있음
5. Early stopping
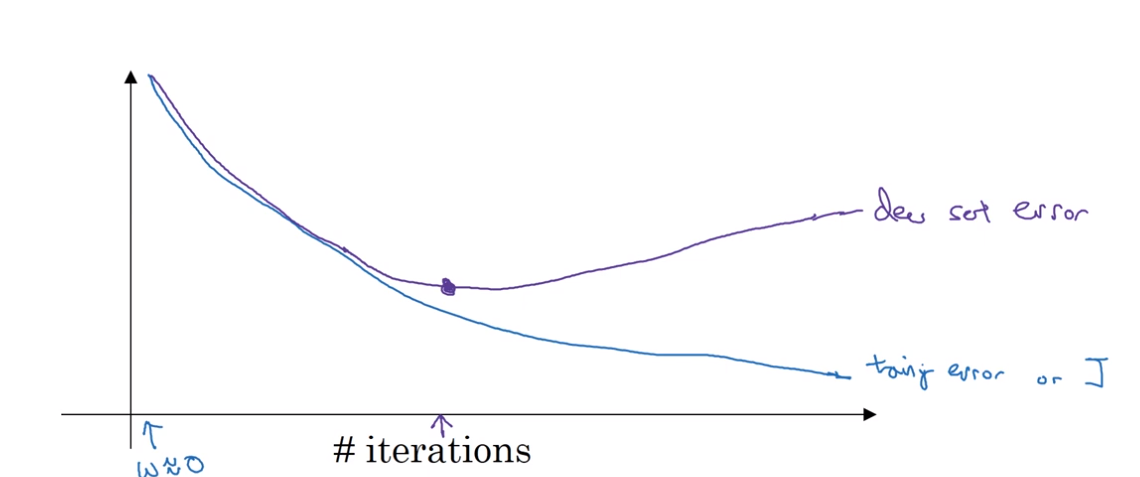
반복이 진행될 수록 매개변수 w의 값은 점점 커짐. 조기종료를 통해서 w가 중간 크기를 가질 수 있도록 함.
l2정규화처럼 매개변수 w에 대해 더 작은 노름을 갖는 신경망을 선택함으로써 과대적합을 막을 수 있음. dev set가 최적값을 가지는 순간에 중단함.
optimize cost function j - 최솟값을 찾는 것
not overfit - 분산을 줄이는 것
직교화 -> 한번에 하나의 할일만 생각. 조기 종료의 단점은 두가지 문제를 섞어버려서 비용함수를 최적화하는 것을 멈춤. 서로 다른 방법을 제시하는 것이 아니라 복합적인 방법을 제시.
조기 종료의 대안은 l2 정규화를 사용하는 것임.
참고
- 행렬 norm (https://bentist.tistory.com/28)
- 딥러닝에서의 Regularization : Weight Decay, Batch Normalization (https://mvje.tistory.com/80)
- Regularization (https://pozalabs.github.io/Regularization/)
- Other Regularization Methods (C2W1L08) _ Andrew nghttps://www.youtube.com/watch?v=BOCLq2gpcGU
- Dropout Regularization (C2W1L06)_ Andrew_nghttps://www.youtube.com/watch?v=D8PJAL-MZv8)
- Norm (wikipedia) (https://en.wikipedia.org/wiki/Norm_(mathematics))
- https://medium.com/analytics-vidhya/journey-of-gradient-descent-from-local-to-global-c851eba3d367
'인공지능 개념' 카테고리의 다른 글
| 손실함수(Loss Functions), MAE, MSE, L1, L2, cross entropy (0) | 2023.07.14 |
|---|---|
| 가중치 초기화 (0) | 2023.07.14 |
| bias and variance/underfitting and overfitting (0) | 2023.07.10 |
| 경사하강법(Gradient Descent), 최적화 알고리즘(Optimizer) (0) | 2023.07.09 |
| backpropagation(오차역전파) 및 문제점(활성화 함수, sigmoid, relu, tanh) (0) | 2023.07.08 |


