
Bamboo is coming
경사하강법(Gradient Descent), 최적화 알고리즘(Optimizer) 본문
경사하강법(Gradient Descent)이란
- 인공지능의 지도학습에서 입력 데이터와 정답값을 제공한 후 주어진 입력 데이터의 정답에 근사한 예측값을 만들어 내는 것이 최종 목표이다.
- 따라서, 정답값에 근사한 예측을 하기 위해 차잇값을 줄여나가야 하는데 예측값과 실제 정답값 사이의 차잇값을 손실 함수(loss function)으로 표현한다.
- 이 손실함수를 최소화하는 과정을 최적화(optimization)이라고 하고 최적화를 수행하는 알고리즘은 최적화 알고리즘(optimizer)로 불린다.
- 최적화 알고리즘은 손실함수의 기울기를 이용하여 손실함수 값이 최저가 되는 방향으로, 자세히는 기울기가 가르키는 반대 방향 즉, 하강하는 방향으로 학습률(learning rate)만큼 가중치를 업데이트하는 알고리즘이다. 이를 경사하강법(Gradient Descent)이라고 부르는데 현재는 이것이 최적화 기법의 중심에 있다.
- 학습률은 step size라고도 하는데, 여기서 학습률이 너무 크면 overshooting으로 최소 지점을 지나치는 경우가 발생하고 반대로 학습률이 너무 작으면 시간이 너무 오래 걸려서 학습이 제대로 이루어지지 않는다.
- 기본적으로 이 학습률을 효율적으로 정하는 방법이 학습률 감소(Learning Decay)로 초반엔 높은 학습률로 시작해 학습률을 조금씩 낮춰 작게 학습하는 방법이다.
- 하지만 내리막길을 생각했을 때처럼 경사가 가파를 때(변화가 클 때) 조금씩 이동하고 경사가 완만할 때(변화가 작을 때) 많이 이동해야 빠르게 최저점에 도달할 수 있다. 이를 적응적 학습률 감소(Adaptive Learning Decay)라고 한다.
- 경사하강법은 ⑴최대 반복 횟수에 도달했거나 ⑵기울기의 크기가 특정 임계값 이하로 떨어지거나(수렴에 가까운 상태) ⑶기울기가 0에 가까워지면 학습을 종료한다.
- 여기서 논쟁의 여지가 있는 것은 ⑶ 기울기가 0에 가까운 지점이 Local Minimum인지 Global Minimum인지 Saddle Point인지 인공지능이 알기 쉽지 않다는 것이다.
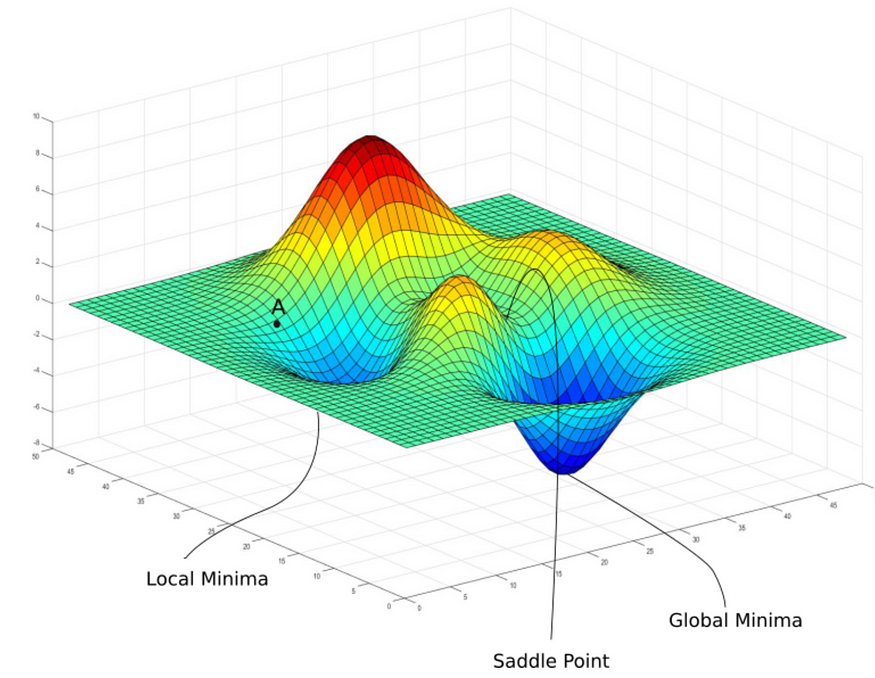
- 위 사진을 보면 3차원 벡터에서는 다양한 굴곡이 있고 이중에 우리가 목표하는 지점은 Global Minima이다.
- Local Minima나 Saddle point 역시 기울기가 0인 지점으로 최저값을 찾았다고 착각하기 쉽다.
- Local Minima: 함수의 특정 지점에서 주변보다 낮은 값을 가지고 그 지점 근방에서 함수의 최솟값을 가진다.
- Saddle Point: 함수의 특정 지점에서 일부 방향에서는 최소값을 가지고, 다른 방향에서는 최댓값을 가진다.
- 고차원에서는 Local Minima보다 Saddle Point가 더 문제가 된다. 차원이 증가함에 따라 saddle point의 수가 급격히 늘어나기 때문에 일부 방향에서 기울기가 0이고 다른 방향에서 기울기가 양수 또는 음수인 특성 때문에 특히 벗어나기 힘들다.
Optimizer(최적화 알고리즘)
Optimizer는 크게 학습률의 조정을 기준으로 수동으로 학습률을 조정하는 Gradient Descent와 자동으로 학습률을 조정하는 Adaptive로 나뉜다.
1. Gradient Descent(경사하강법)
수동으로(manually) 학습률을 조정하는 알고리즘은 손실함수(목적함수)의 기울기를 계산하는 데에 사용되는 데이터 크기에 따라 구분할 수 있다.

1.1. BGD(Batch Gradient Descent)
- BGD는 vanilla gradient descent라고도 불리는데 간단하게 모든 데이터의 손실함수를 계산해서 딱 1번 업데이트를 수행한다.
- 장점
- 업데이트에 대한 계산량은 적은 편이다.
- 전체 데이터셋에 대해 계산하기 때문에 optimal로의 수렴이 안정적이다.
- 단점
- 모든 데이터셋에 대한 기울기를 미분해서 한 번만 업데이트를 하기 때문에 업데이트 속도가 매우 늦다.
- local optimal에 가면 빠져나오기가 힘들다.
- 전체 데이터셋에 대한 에러를 저장해야되기 때문에 많은 메모리가 필요하다.
1.2. SGD(Stochastic Gradient Descent)
- BGD의 변형으로 전체 데이터 세트 가운데 random으로 하나에 데이터의 손실함수의 기울기를 계산하여 업데이트를 진행한다.
- 장점
- 빠르게 shooting이 일어나 lcoal optimal에 빠질 위험이 적다.
- 손실함수 계산후 업데이트하는 시간이 짧아 수렴 속도가 상대적으로 빠르다.
- 단점
- global optimal을 찾지 못할 수 있다.
- 데이터를 한 개씩 처리하기 때문에 GPU의 성능을 전부 활용할 수 없다.
1.3. MGD(Mini-bach Gradient Descent)

- 전체 데이터셋을 작은 미니 배치로 나누어 하나의 미니 배치의 학습에 한 번씩 업데이트한다.
- 한 번에 120만개의 데이터를 학습시킨다고 할 때 256개짜리의 배치만을 이용해 gradient를 구하고 파라미터 업데이트를 한다.
- 이미지들이 비슷한 값을 가지고 있다고 가정했을 때 미니 배치에서만 계산하는 gradient는 모든 데이터를 써서 구하는 근사값으로 쓰일 수 있고
- 장점
- 여러 샘플을 한 번에 처리해 병렬 처리가 가능하다.
- BGD에 비해 메모리 사용량을 효율적으로 관리할 수 있다.
- SGD보다 노이즈 값이 적으며 일반화 성능이 좋다.
- 더 자주 파라미터를 업데이트하여 더 빠르게 최적값에 수렴할 수 있다.
- 단점
- 일부의 경우 SGD보다 local minimum에 빠지기 쉽다
- 배치 크기에 따라 학습 속도와 성능이 달라진다.
1.3.1 BGD VS SGD VS MGD
예를 들어, total dataset 1000개, batsize 10개, 10 epoch를 학습시킨다고 하자.
1. BGD - 전체 데이터셋을 큰 배치로 취급하여 10 epoch동안, 10번 업데이트
2. SGD - 배치마다 랜덤으로 값 1개에 대해서 업데이트하므로, 100 iteration * 10 epch = 1000번 업데이트
3. MGD - 배치마다 평균으로 업데이트하므로 100 iteration * 10 epoch = 1000번 업데이트
2. Adaptive
학습률을 자동으로(automatically) 업데이트해주는 Optimizer다.
하지만 Keras같은 라이브러리는 advanced한 학습을 위해 직접 세팅하도록 하기도 한다.

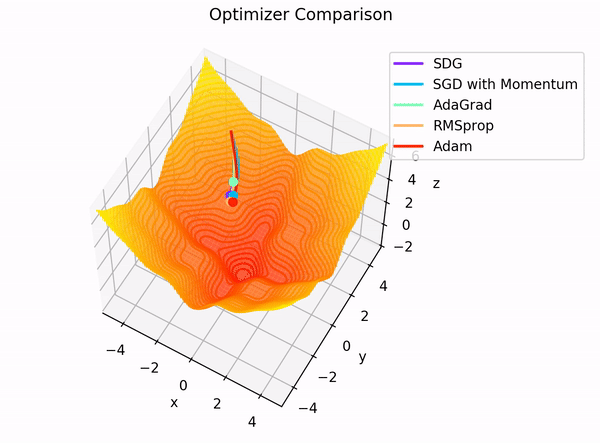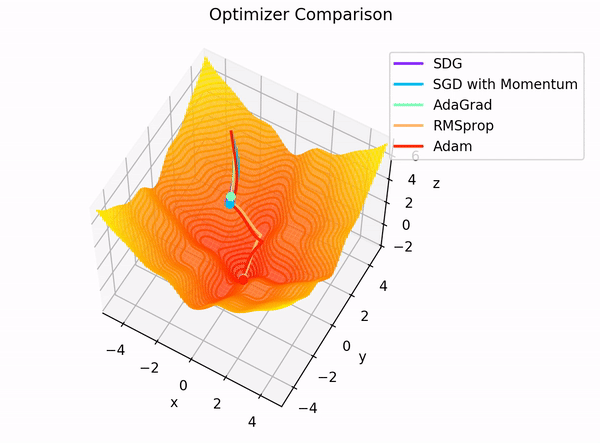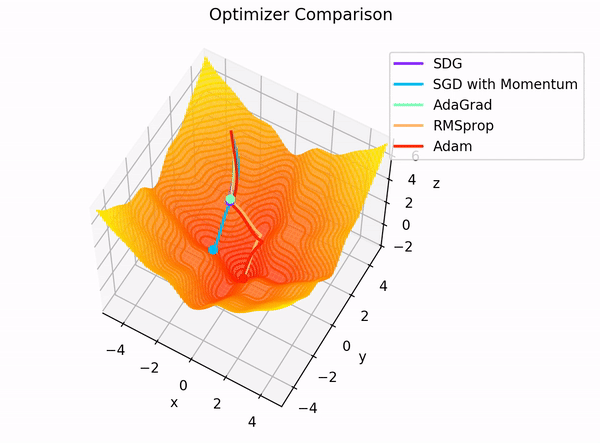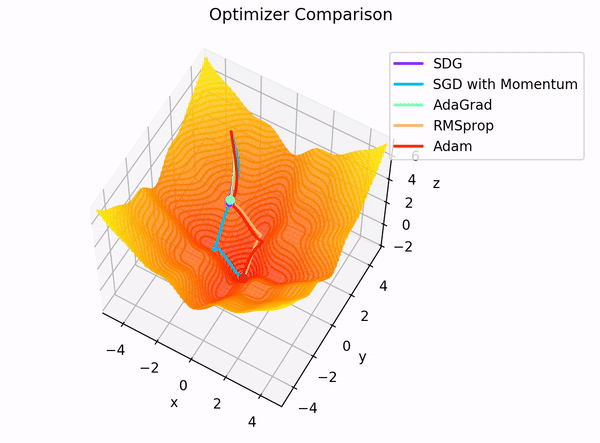
2.1. Momentum
가속도가 추가된 경사하강법
v: velocity(속도)
$V_t = \gamma ×V_{t-1}+lr×gradient
W=W-V_t$
장점
같은 방향으로 업데이트가 여러 번 일어나게 되면 해당 방향으로 점점 가속도가 붙어 더 많이 업데이트함으로써 빠르게 최소 지점에 가까워진다.
2.2. Nesterov momentum(네스테로프 모멘텀)
가속도에 대한 변수 업데이트 + 기울기 업데이트
$ gradient = gradient( \theta -\gamma \times V_{t-1})
V_t = \gamma ×V_{t-1}+lr×gradient
W=W-V_t$
현재 위치에 gradient를 이용하는 것이 아니고 현재 위치에서 속도만큼 전진 후의 그래디언트를 이용
-> 모험적으로 진행 후 에러를 교정한다.
2.3. Adagrad(Adaptive Gradient)
기울기 누적 변수(Gradient accumulation variable)을 도입해 기존에 기울기가 적게 변한 변수는 큰 학습률을 적용하고 많이 변한 변수는 작은 학습률을 적용한다.
업데이트가 많이 필요한 변수에 대해 적용시 학습이 충분히 안될 가능성이 크다.
2.4. Adadelta
부식률 변수 추가.
기울기 소실이 발생하지 않음.
고정된 과거 기울기를 도입함.
2.5. RMSprop
Adadelta와 매우 비슷
과거 기울기를 다루는 것에 차이가 있음
2.6. Adam
Adadelta + RMSprop의 장점을 합친 것으로 모멘텀처럼 기하급수적으로 감소하는 기울기 평균을 저장한다.
기울기의 1차 모멘트(평균), 2차 모멘트(분산)을 계산하여 변수 업데이트
2.5.
2.7. Gradient descent vs Adaptive
보통 Adam이 최근에 나온 가장 좋은 기술로 general하게 사용되고 있다. 하지만 최근 많은 연구들에서 SGD와 좋은 학습률 감소 기법(good learning rate annealing schedule)을 결합하면 좋은 성과를 낸다고 한다.
참고
https://scribblinganything.tistory.com/705
SGD, BGD, mini BGD란? 차이를 예제로 쉽게 이해하기(Stochastic Gradient Descent, Batch, Epoch, Iteration)
목차 SGD란?(Stochastic Gradient Descent) SGD(Stochastic Gradient Descent)는 머신 러닝에서 가장 많이 사용되는 최적화 알고리즘 중 하나입니다. 이 알고리즘은 모델의 파라미터(Parameter)를 조정하여 손실 함수
scribblinganything.tistory.com
https://light-tree.tistory.com/133
딥러닝 용어정리, MGD(Mini-batch gradient descent), SGD(stochastic gradient descent)의 차이
제가 공부한 내용을 정리한 글입니다. 제가 나중에 다시 볼려고 작성한 글이다보니 편의상 반말로 작성했습니다. 잘못된 내용이 있다면 지적 부탁드립니다. 감사합니다. MGD(Mini-batch gradient descent
light-tree.tistory.com
https://brunch.co.kr/@linecard/560
앤드류 응의 머신러닝(17-2): 확률적 경사하강법
온라인 강의 플랫폼 코세라의 창립자인 앤드류 응 (Andrew Ng) 교수는 인공지능 업계의 거장입니다. 그가 스탠퍼드 대학에서 머신 러닝 입문자에게 한 강의를 그대로 코세라 온라인 강의 (Coursera.org
brunch.co.kr
https://towardsdatascience.com/7-tips-to-choose-the-best-optimizer-47bb9c1219e
7 tips to choose the best optimizer
Based on my experience.
towardsdatascience.com
https://velog.io/@cha-suyeon/DL-%EC%B5%9C%EC%A0%81%ED%99%94-%EC%95%8C%EA%B3%A0%EB%A6%AC%EC%A6%98
The journey of Gradient Descent — From Local to Global_medium
https://towardsdatascience.com/optimizers-for-training-neural-network-59450d71caf6
'인공지능 개념' 카테고리의 다른 글
| 손실함수(Loss Functions), MAE, MSE, L1, L2, cross entropy (0) | 2023.07.14 |
|---|---|
| 가중치 초기화 (0) | 2023.07.14 |
| Regularization 정규화 (0) | 2023.07.10 |
| bias and variance/underfitting and overfitting (0) | 2023.07.10 |
| backpropagation(오차역전파) 및 문제점(활성화 함수, sigmoid, relu, tanh) (0) | 2023.07.08 |


