
Bamboo is coming
bias and variance/underfitting and overfitting 본문
1. 정의
- Bias
모델을 통해 얻은 예측값과 실제 정답과의 차이 평균, 예측값이 실제 정답값과 얼마나 떨어져 있는 지를 나타냄 - Variance
다양한 데이터 셋에 대해 예측값이 얼마나 변할 수 있는 지에 대한 Quantity의 개념. 예측값이 퍼져있는 정도
2. bias와 variance의 관계(Bias and Varaince Trade-Off)
- bias와 variance는 모델의 복잡도와 관련이 있다.
- bias가 높으면 underfitting이 되고 variance가 높으면 overfitting이 발생하기 때문에 적당한 수준의 bias와 variance를 만들기 위해 적정한 수준에서 모델의 학습을 종료시켜야 한다.
2.1. 예측값 분포
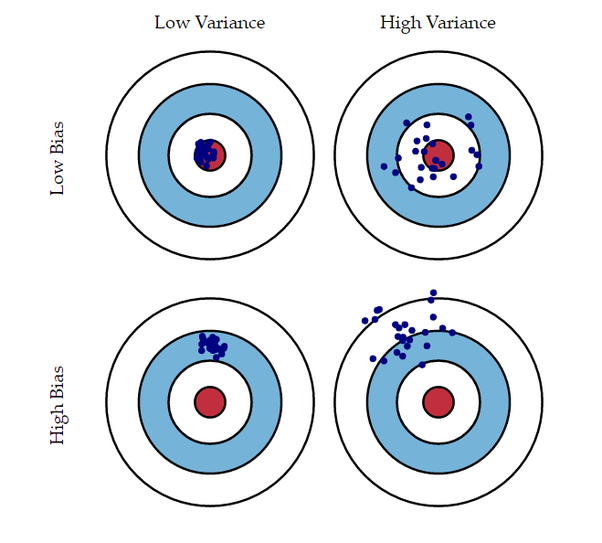
- 그림에서 볼 수 있듯이 Low Bias & Low Variance가 가장 정답값(빨간 원)과 근접함.
2.2. Regression(회귀)
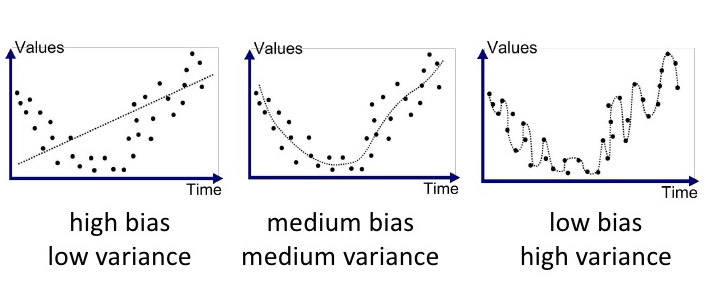
- 회귀 문제에서는 그래프와 정답값 사이의 차이로 bias와 variance를 알 수 있다.
- high bias & low variance는 예측 그래프가 실제 정답값과 많이 다르고(high bias) 예측그래프의 변화가 크지 않다.(low variance)
- low bias & high variance는 예측 그래프가 실제 정답값에 거의 일치(low bias)하지만, 예측 그래프가 많이 퍼져 있다.(high variance)
2.3. Classification(분류)

- 분류 문제의 경우 정답을 분류해내는 선을 찾아야 한다.
- high bias(underfitting) - 정답값을 제대로 분류해내지 못함. 그래프가 다소 분류율이 낮음
- high variance(Overfitting) - 정답값을 지나치게 분류해서 복잡한 선이 나왔음.
그래프를 보면 알 수 있듯이 high bias(underfitting)의 그래프는 선이 지나치게 단순해서 train dataset에 대한 정확도가 떨어지고 high variance(overfitting)의 그래프는 선이 지나치게 복잡해서 train dataset에 대한 정확도가 매우 높음.
선이 지나치게 복잡한 것은 generalization의 성능이 떨어져서 처음 보는 데이터에 대한 예측을 못할 가능성이 높고,
선이 지나치게 단순한 것은 모델의 성능이 떨어져서 전체적인 데이터의 예측률이 떨어진다.
따라서, 최적화된 학습을 하기 위해서는 high bias와 high variance의 중간 지점을 찾아야 한다.
3. Overfitting에 영향을 끼치는 요소
3.1. Model complexity(모델 복잡도)
- 복잡도는 얼마나 복잡한 패턴을 학습할 수 있는지를 나타낸다.
- 모델의 복잡도는 모델의 구조와 하이퍼파라미터에 의해 결정된다.
- 예) 선형 회귀 vs 다항 회귀, 의사결정 트리의 깊이, 신경망의 은닉 계층 개수 등
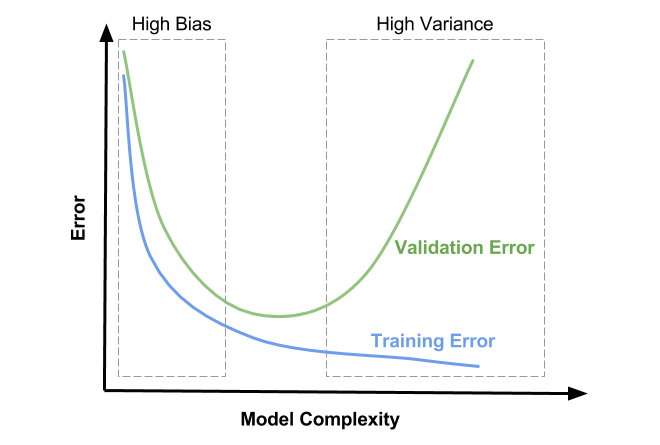
- train을 하는 동시에 validation 데이터의 error를 확인하여 validation error의 추이를 확인하여 overfitting, underfitting의 여부를 알아낸다.
- validation error가 감소하다가 다시 증가하기 시작하는 지점이 overfitting의 시작점이므로 그 지점이 최적화된 학습 지점이다.
- 모델의 복잡도가 높아질수록 training error는 감소하고 validation error는 증가한다.
- 복잡도가 높아질수록 training error는 overfitting되어 generalization(일반화)가 떨어지고 validation error와의 차이가 커진다.
- High Bias와 High Variance의 중간 지점이 optimal model complexity라고 할 수 있다.
- 적절한 복잡도를 선택하는 것은 모델의 성능을 최적화하는 데 중요한 고려사항이다.
3.2. Model capacity
- Model capacity is ability to fit variety of functions
- 파라미터 갯수를 의미한다.
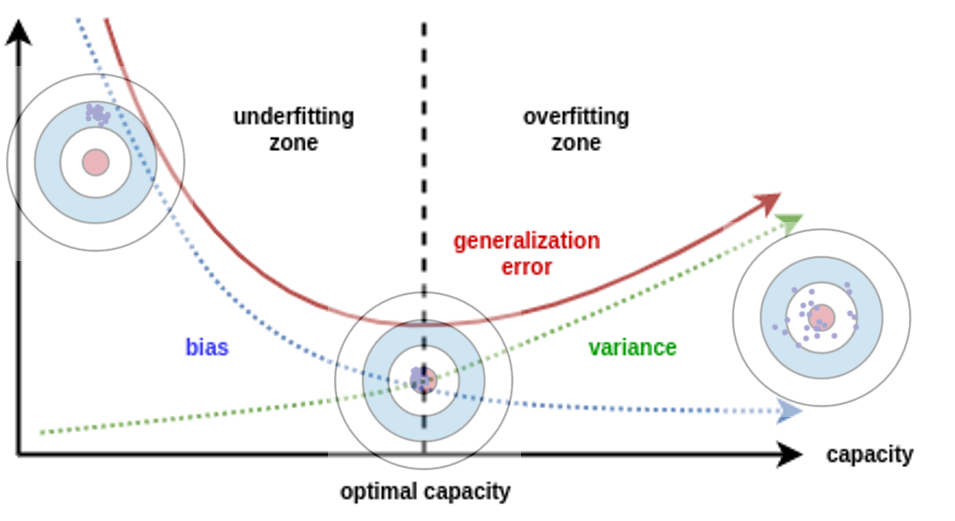
- capacity는 모델 복잡도에 기여하는 요소 중에 하나이다.
- 파라미터 즉, capacity을 올바르게 조정해야 최적의 fitting 지점을 찾을 수 있다.
- 곡선에서 가장 최소가 되는 지점이 low bias & low variance(optimal capacity)를 만족하는 지점이다.
- = bias 곡선과 variance 곡선이 만나는 지점이 optimal capacity인 지점
3.3. Degree of polynomial d(다항차수 d)

- degree 역시 오버피팅에 영향을 끼친다. capacity와 degree 모두 모델 복잡도에 관여하는 요소이다.
- degree(차수)를 높이면 식의 표현식이 더 증가해서 성능이 증가하지만 데이터 분포에 비하여 너무 표현력이 증가하면 overfitting이 발생할 수 있다.
- low degree: 모델이 복잡하지 않아 데이터의 패턴을 완전히 포착하지 못하여 underfitting 발생. 낮은 차수의 다항식은 높은 편향을 가질 수 있다.
high degree: 모델이 너무 복잡하여 훈련 데이터에 과도하게 적합하는 overfitting 발생. 높은 차수의 다항식은 높은 분산을 가질 수 있다.
3.4. Regularization
3.4.1 $\lambda$ 크기에 따른 Bias and variance
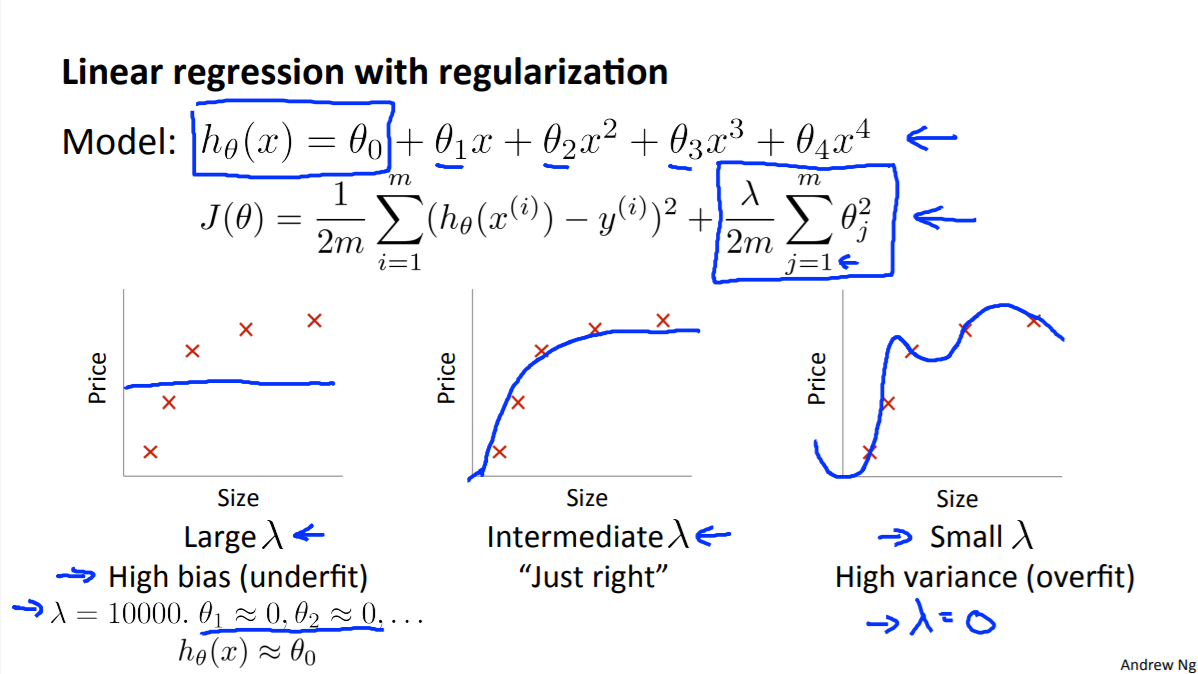
- 수식 설명
- θ는 모델 파라미터 또는 가중치
- $h_ \theta (x)=\theta_0+\theta_1x+\theta_2x_2+ \ldots +\theta_nx_n$는 예측값
h는 Hypothesis(가설)의 약자 - $\theta_0$는 편향
- x는 입력값
- J(θ)는 손실함수
- $\theta_1,\ldots,\theta_m$는 가중치
- 정규화(regularization)는 모델의 복잡도를 낮춰 새로운 데이터에 대한 예측 성능을 향상시키는 것이 목적이다.
- λ 가 아주 큰 값을 가지게 되면 $\theta_0$(편향)을 제외한 $\theta_1,\ldots,\theta_m$에 대해서는 0에 수렴하여 $h_\theta(x)\approx \theta_0$으로 학습이 안되게 된다.
- (위 그림에 나온 L2 regularization은 비용 함수를 최소화하기 위해 가중치는 0에 가까워져야 한다.)
- 그리고 $\theta_0$(편향)의 값만 남게 되어 high bias의 그래프처럼 수평선 그래프가 그려지게 된다.
- $\lambda$가 너무 크면 나머지 가중치들의 학습이 잘 이루어지지 않는 이유
- 정규화 항의 영향력 증가
λ 값이 크면 정규화 항의 영향력이 비용 함수에 대해 상대적으로 커진다. 가중치에 대한 패널티를 나타낸다. - 가중치 축소
λ 값이 크면, 정규화 항은 비용 함수를 최소화하기 위해 가중치를 가능한 한 작게 만드는 경향이 있다. 이는 모델이 너무 단순화되고, 복잡한 패턴을 포착하지 못하게 만든다. - 과소적합 (Underfitting)
λ 값이 너무 크면, 모델은 훈련 데이터에 대해 너무 일반화되어 과소적합될 수 있다. 이는 모델의 편향이 높아지고 분산이 낮아지는 결과를 초래하며, 모델이 훈련 데이터의 중요한 패턴을 학습하지 못하게 된다.
- 정규화 항의 영향력 증가
따라서 $\lambda$는 0부터 시작해서 점점 크기를 올리면서 최적값을 찾아야 최적의 값을 찾을 수 있다.
3.4.2 $\lambda$ 크기에 따른 training error and validation error
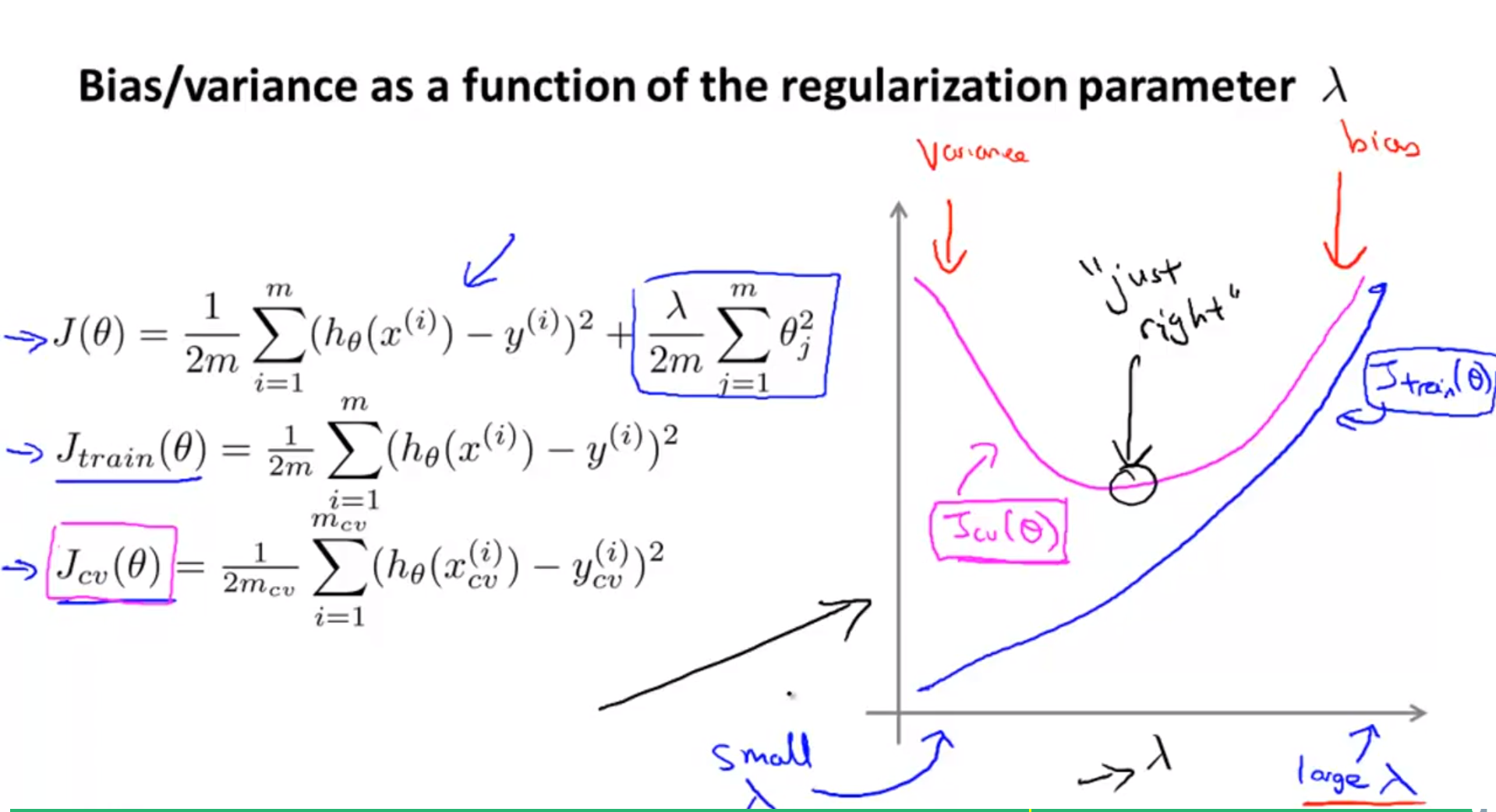
- train error의 경우 $\lambda$의 크기가 커질수록 error의 크기가 더 커지게 된다.
- cost function을 보면 알 수 있듯이 regularization term은 항상 양수 값(제곱)이 더해지기 때문이다.
- 반면 validation error의 경우 $\lambda$가 점점 커질수록 error가 줄다가 다시 커지게 됨을 알 수 있다.
- $\lambda$가 매우 작은 값에서 적당한 값으로 커지게 되면 overfitting 문제가 조금씩 해결되면서 validation error가 줄어들게 된다.
- 하지만 적정 크기의 regularization parameter 보다 값이 커지게 되면 cost function 의 형태와 같이 항상 error에 양의 값이 더해지게 되므로 error 값이 증가하게 된다.
- 즉, regularization parameter가 적당한 값까지 증가할 때에는 variance 문제가 해결되는 것이 error에 값이 더해지는 것 보다 효과가 있어서 error가 줄어든다.
- 반면 최적점을 지날 만큼 parameter 값이 커지게 되면 bias 문제에 빠지게 되고 error값에 더해지는 regularization값도 커지게 되어 error가 증가하게 된다.
3.5. Learning Curves(size of training set)
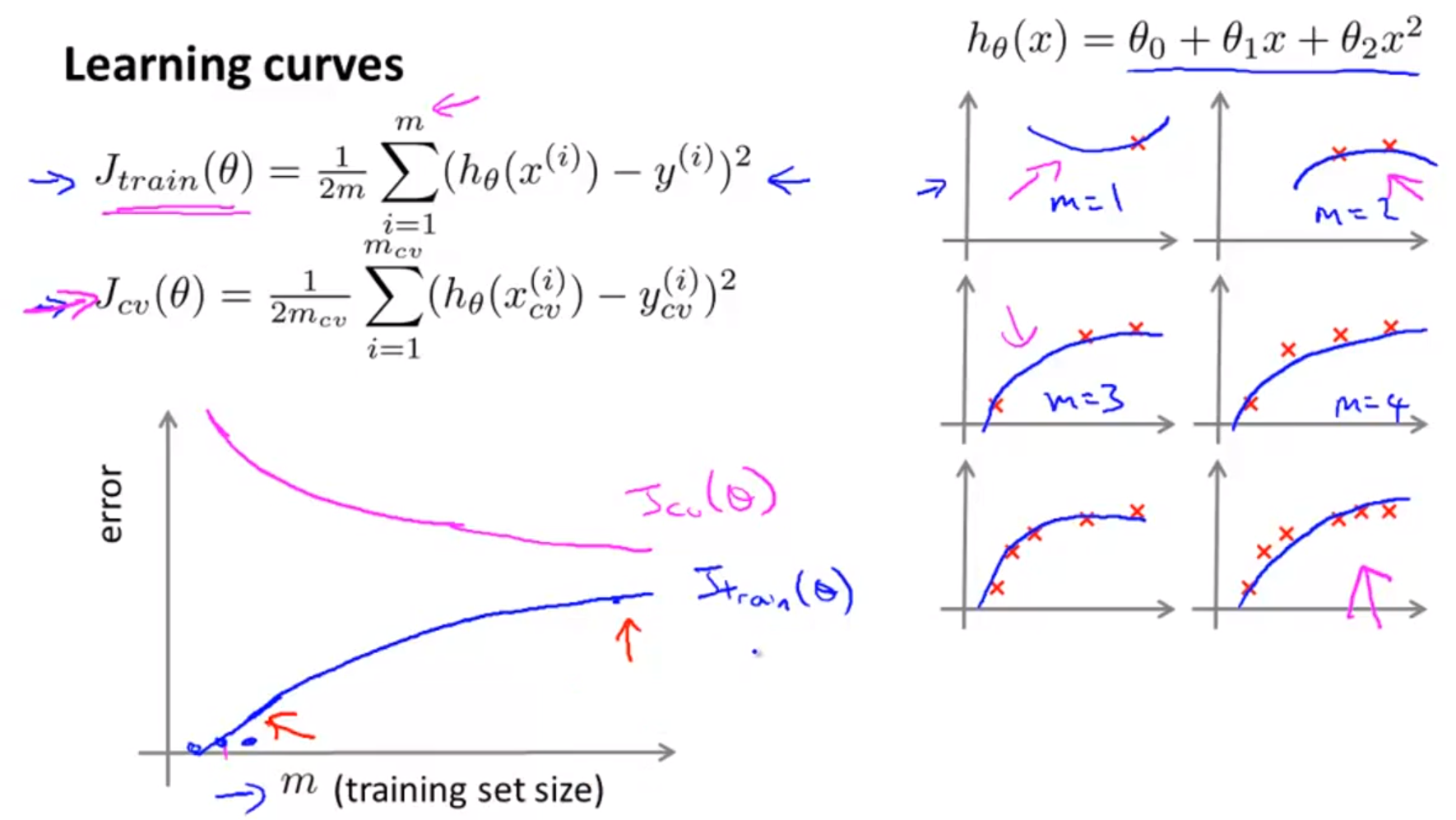
- 슬라이드의 오른쪽은 데이터의 개수에 따른 그래프의 모양 변형을 나타내는데, 그래프를 보면 데이터가 많아질수록 파라미터가 데이터에 맞춰 학습이 되기 때문에 점점 더 데이터의 데이터 모집단의 분포에 가까워진다.
- 슬라이드 왼쪽 하단은 training set와 error의 그래프이다. 학습 데이터 셋의 크기가 매우 작은 경우는 error가 매우 작다. 왜냐하면 데이터가 너무 작기 때문에 error가 발생할 데이터의 수가 작기 때문이다.
- 데이터가 점점 증가할수록 training error는 점점 증가하다가 정체된다. 이는 일반적인 training error의 변화 과정이다.
- validation error는 학습 데이터가 적을 때는 상당히 크다. 아주 적은 데이터로 모델을 학습하였기 때문에 generalization(일반화) 성능이 매우 떨어지기 때문이다.
- 그러다가 학습 데이터의 갯수가 늘어날 수록 generalization 성능이 높아져 training error보다는 크지만 유사한 수준으로 validation error가 감소한다.
4. 정리
4.1 Bias problem
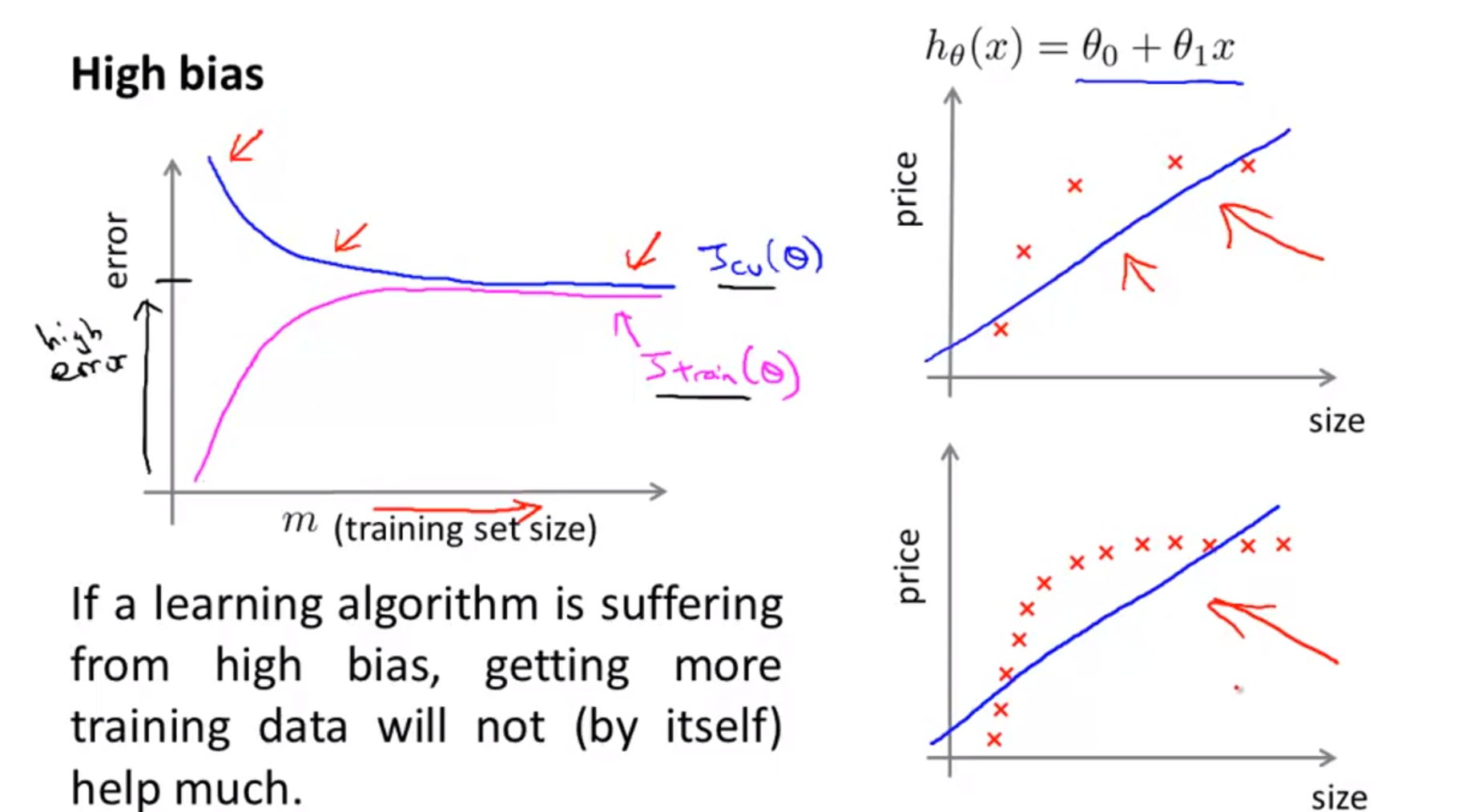
- bias 문제는 기본적으로 모델의 복잡도가 낮아서 표현력이 안 좋기 때문에 발생한다.
- 위 그래프처럼 모델이 단순 선형이라고 가정하면 데이터 분포를 적합하게 표현할 수가 없다.
- 이런 경우에 학습 데이터 크기를 늘리더라도 bias 문제를 해결하기는 어렵다.
4.2 Variance problem
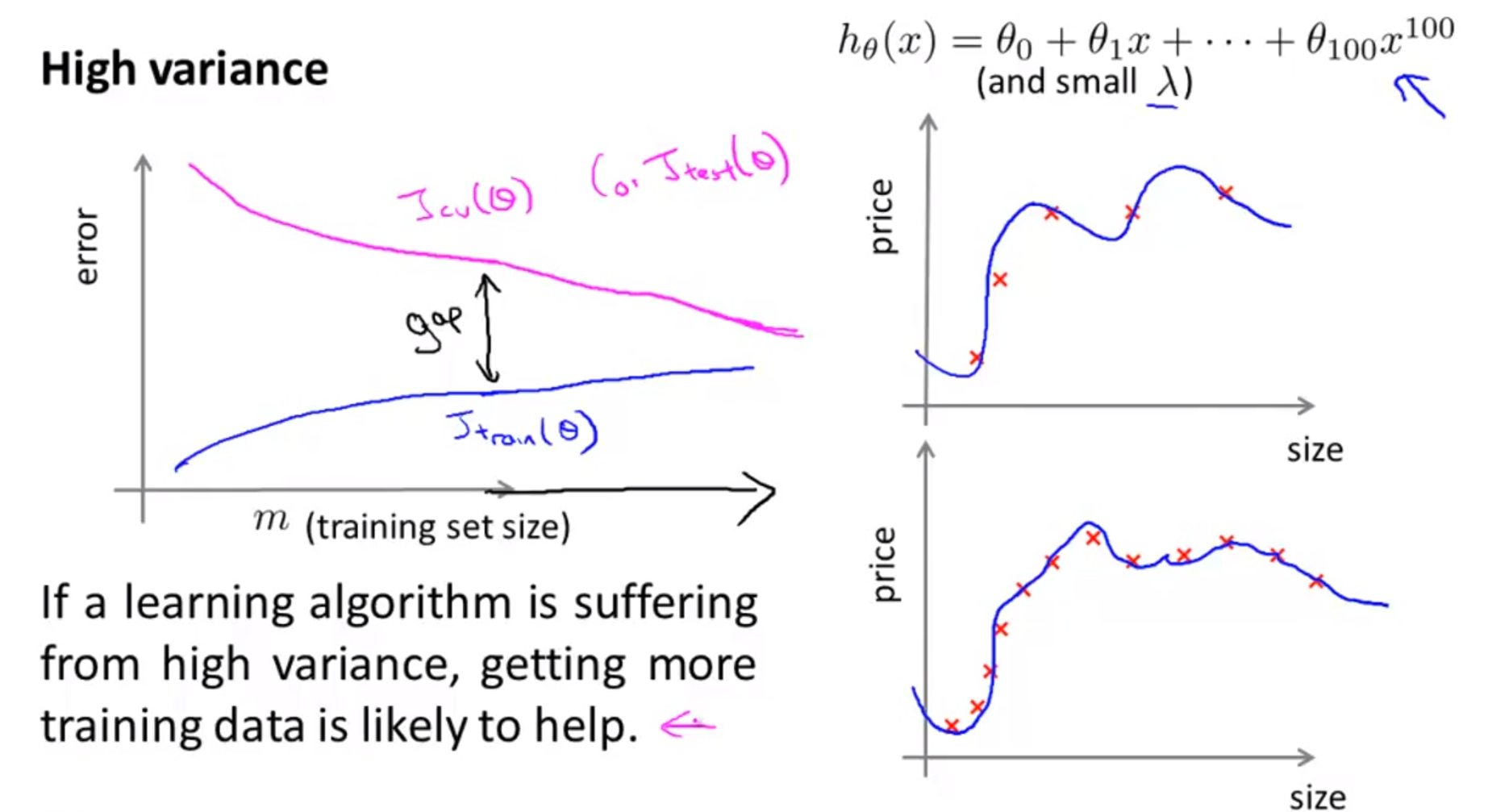
- variance 문제는 기본적으로 학습 데이터에 비하여 너무 모델의 복잡도가 높아서 모델이 너무 과하게 학습한 문제(overfitting)으로 인해 발생한다.
- 학습 데이터의 크기를 늘려서 validation/test error를 줄인다는 것은 variance 문제에 상당히 적합하다.
- 표현력이 너무 좋아서 문제가 된 모델이 더 많은 학습데이터를 통하여 데이터 분포를 정확하게 표현하게 되므로 generalization 성능도 향상된다. -> 즉 validation/test error가 줄어든다.
4.3. Debugging a learning algorithm
4.3.1. 알고리즘에 따른 debug

high variance(overfitting) 해결 방법
- Get more training examples
- Try smaller sets of features
- Try increasing $\lambda$
high bias(underfitting) 해결 방법
- Try getting additional features
- Try adding polynomial features
- Try decreasing $\lambda$
4.3.2. 네트워크 사이즈에 따른 Debug
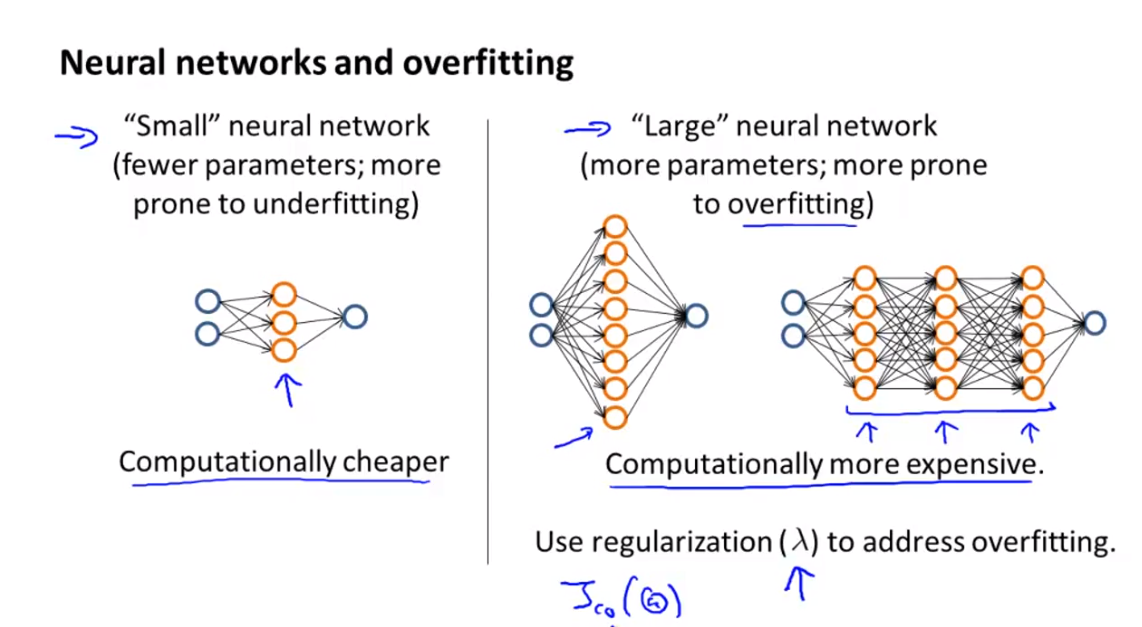
- Neural Network에서 layer의 갯수와 parameter의 갯수는 비례한다.
- 작은 neural network; layer(parameters)의 갯수가 작으면 계산 비용은 작지만 underfitting에 빠지기 쉽다.
-> 해결 방법: layer 추가 - 큰 neural network; layer(parameters)의 갯수가 많으면 계산 비용도 많이 들고 overfitting이 되기 쉽다.
-> 해결 방법: 데이터 갯수를 늘리거나 regularization 추가, layer 갯수 줄이기
정리
Bias problem = underfitting
Variance problem = overfitting
참고
https://gaussian37.github.io/machine-learning-concept-bias_and_variance/
https://m.blog.naver.com/PostView.naver?blogId=tkdldjs35&logNo=221781662024&proxyReferer=https:%2F%2Fwww.google.co.kr%2F
https://opentutorials.org/module/3653/22071
https://velog.io/@euisuk-chung/Inductive-Bias란
'인공지능 개념' 카테고리의 다른 글
| 손실함수(Loss Functions), MAE, MSE, L1, L2, cross entropy (0) | 2023.07.14 |
|---|---|
| 가중치 초기화 (0) | 2023.07.14 |
| Regularization 정규화 (0) | 2023.07.10 |
| 경사하강법(Gradient Descent), 최적화 알고리즘(Optimizer) (0) | 2023.07.09 |
| backpropagation(오차역전파) 및 문제점(활성화 함수, sigmoid, relu, tanh) (0) | 2023.07.08 |


