
Bamboo is coming
InST git 설치기(InST 모델 설명 및 실행기) 본문
InST https://github.com/zyxElsa/InST
GitHub - zyxElsa/InST: Official implementation of the paper “Inversion-Based Style Transfer with Diffusion Models” (CVPR 202
Official implementation of the paper “Inversion-Based Style Transfer with Diffusion Models” (CVPR 2023) - GitHub - zyxElsa/InST: Official implementation of the paper “Inversion-Based Style Transfer...
github.com
InST는 textual_inversion( An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion 기반의 모델이다.
textual inversion은 dreambooth와 비슷한 파인튜닝 방식을 뜻하는 것이다. 사용자가 학습시키는 이미지와 텍스트를 매칭시키고 해당 이미지에 해당하는 특징들을 텍스트를 통해 개념을 설명하는 방식이다. 텍스트 투 이미지 모델이라고 하는데 그럼 CLIP 모델 간의 주요 차이점으로는 관계성, 생성의 차이가 있다. CLIP은 이미지와 텍스트 간의 관계를 이해하는 분류하는 classifier 모델이고 Textual Inversion은 개별적 개념이나 개체를 학습시키는 Generative 모델이다.
예를 들어 "내 애완견 구름이"를 학습시킨다고 했을 때 textual inversion은 "애완견"이라는 클래스를 가진 "구름이"를 따로 학습하여 생성하는 것을 목표로 하고 CLIP은 "구름이"가 "애완견" 클래스에 속하는구나!를 인식하고 구름이를 입력했을 때 애완견으로 분류하는 것을 목표로 한다.
그래서 InST가 이 textual inversion을 가지고 무엇을 하냐 함은 attention을 기반으로 하는 textual inversion 을 사용하여 이미지의 주요 특징을 학습하고 이미지를 학습가능한 텍스트 임베딩으로 변환한다. 여기서 textual inversion의 문제점인 단일 이미지로 과적합이 되기 쉽다는 문제를 CLIP으로 해결한다. CLIP이 image embedding과 text embedding 사이에 정렬된 잠재공간을 가지고 있기 때문에 최적화에 용이하다. multi-layer를 사용한 cross attention을 기반으로 하는 학습방법을 도입했다. input 이미지는 CLIP으로 보내진 후 image embedding을 얻고 multi-layer cross attention을을 통해 image embedding에서 key information(text embedding)을 얻을 수 있다. 학습동안 모델은 text embedding을 통해서만 학습한다.
diffusion을 backbone으로 하여 이를 img2img txt2txt의 생성기로 사용될 수 있도록 한다. 이 중에서 textual inversion으로 특정 단어를 기반으로 핵심 특징을 빠르게 학습할 수 있다. 그리고 원본 이미지를 유지하기 위한 stochastic inversion을 사용한다. stochastic inversion을 사용하면 원본 이미지의 핵심적인 특징을 유지하면서도 무작위성을 도입하여 결과 이미지에 변화와 다양성을 줄 수 있다. stochastic inversion은 textual inversion과 별개의 개념인데 stochastic inversion은 이미지 재구성과 변형에 사용되고 textual inversion은 생성 모델에서 텍스트 임베딩을 학습하는 과정을 이야기 한다.
inversion의 영어사전에는 a reversal of position, order, form, or relationship 이라고 표현되는데 stochasitc 과 textual 모두 변환하는 의미를 담고 있어서 inversion이 자주 쓰이는 것 같다.

교수님 과제의 일환으로 구동을 돌렸다.
1. window + gpu(gtx 4070)
찾아본 정보에 의하면 3080 기준으로 한 장당 20분이 걸린다고 한다.
처음에는 윈도우 환경인 친구 컴퓨터에서 돌렸는데 ①SIGUSR1 에러와 ②Distributed package doesn't have NCCL 에러가 발생했다.
그리고, 이 연구의 근간이 되는 textual_inversion github issue에서 windows에서 돌릴 수 있는 우회로를 발견했다.
우회로를 통해 윈도우에서 구동되는 걸 확인했었는데 윈도우라 제약도 있고 너무 오래걸려서 배치사이즈도 학습 개수도 대폭 줄여서 진행했다.
그 결과 선을 뭉개는 듯한 그런 결과가 나왔다.
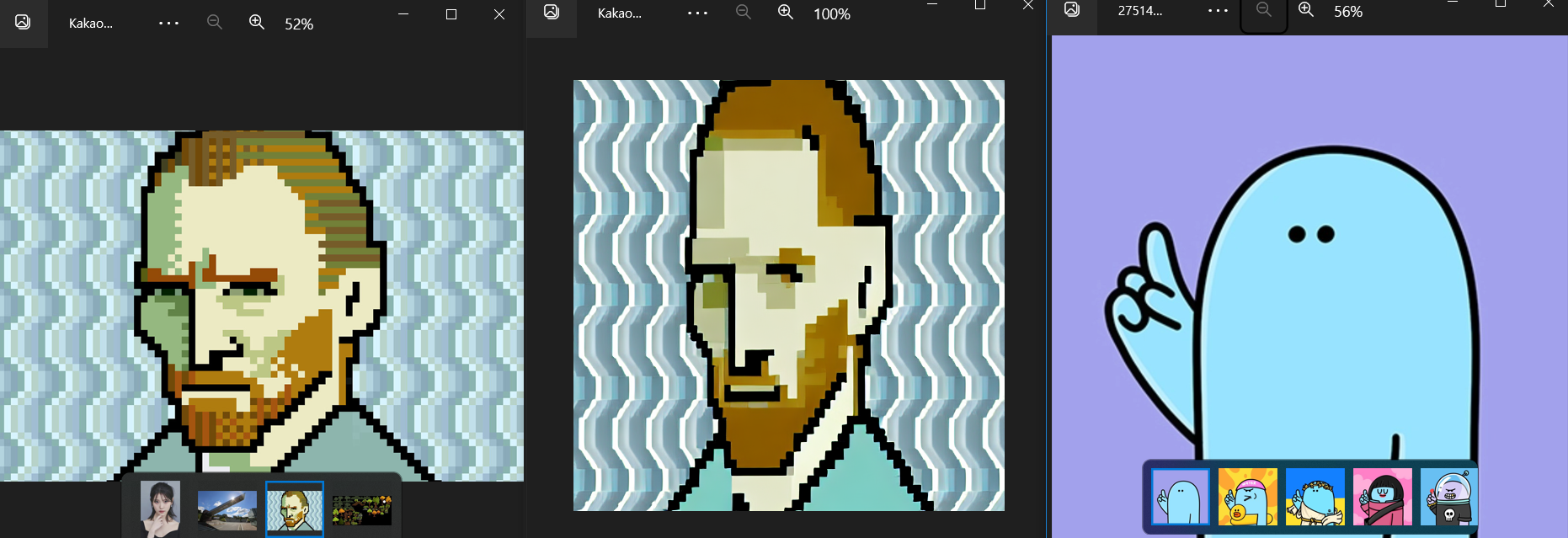
2. Linux + gpu(gtx 1080 4개)
그래서 gtx 1080 4개가 장착된 컴퓨터에 우분투를 설치하고 구동했는데 CUDA out of memory로 구현이 막혔다.
① RuntimeError: CUDA out of memory. Tried to allocate 512.00 MiB (GPU 0; 7.92 GiB total capacity; 6.15 GiB already allocated; 325.62 MiB free; 6.43 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
->
gpu가 4개가 있는데도 불구하고 오류가 나는건 병렬처리가 안되고 있기 때문이라는 생각이 든다.
① - ① 일단 v1-finefune.yaml에서 lightning max_images를 4개로 줄이고 다시 구현해보려고 한다.
-> 안 됨
① - ② maxsize도 줄이고 repeat도 50으로 줄이고
② Restored from ./models/sd/sd-v1-4.ckpt with 592 missing and 2 unexpected keys
-> https://github.com/CompVis/stable-diffusion/issues/271
config 파일에 직접 경로 지정
3. Colab
우선 InST는 ldm(latent diffusion model, 2021)을 기반으로 사용하기 때문에 다음과 같은 실행환경을 가지고 있다.
InST는 2022년 11월에 출간된 논문이다. 수정을 거쳐 2023년 3월이 최신 버전인데 ldm을 사용하는 데에 문제가 좀 많은 것 같다. 출간한 곳은 중국 연구실인데 태국, 독일, 중국 등의 사람들이 참여했다. 해당 연구실에서 ProSpect라는 후속 논문을 발표했는데 여기서도 똑같은 실행 환경을 가지고 있다.
name: ldm
channels:
- pytorch
- defaults
dependencies:
- python=3.8.10
- pip=20.3
- cudatoolkit=11.3
- pytorch=1.10.2
- torchvision=0.11.3
- numpy=1.22.3
- pip:
- albumentations==1.1.0
- opencv-python==4.2.0.34
- pudb==2019.2
- imageio==2.14.1
- imageio-ffmpeg==0.4.7
- pytorch-lightning==1.5.9
- omegaconf==2.1.1
- test-tube>=0.7.5
- streamlit>=0.73.1
- setuptools==59.5.0
- pillow==9.0.1
- einops==0.4.1
- torch-fidelity==0.3.0
- transformers==4.18.0
- torchmetrics==0.6.0
- kornia==0.6
- -e git+https://github.com/CompVis/taming-transformers.git@master#egg=taming-transformers
- -e git+https://github.com/openai/CLIP.git@main#egg=clip
- -e .
가장 큰 문제점은 우선 파이썬의 버전이 고정되어있다는 것이다.
① Colab에 가상환경이 적용되지 않는다.
가상환경이 가능하다는 여러 블로그가 있었지만 conda colab을 사용해도 가상환경 실행을 검증해보면 적용되지가 않았다.

오케이, 그럼 하나하나 설치하면 되지
-> 하나하나 설치해서 다 설치가 됐는데도 module이 없다면서 오류가 떴다. 파이썬 버전도 그렇고 충돌되는게 많은 것 같다.
② python version 실행 불가
colab 내에서 실행되는 /usr/local/conda-meta/pinned 에 적힌 python version 지정 때문에 수정이 되지 않았다. 파일을 삭제해도 그 뿐이고 곧바로 pinned 파일이 생성됐다.
4. Windows + gpu(gtx 4070 1개)
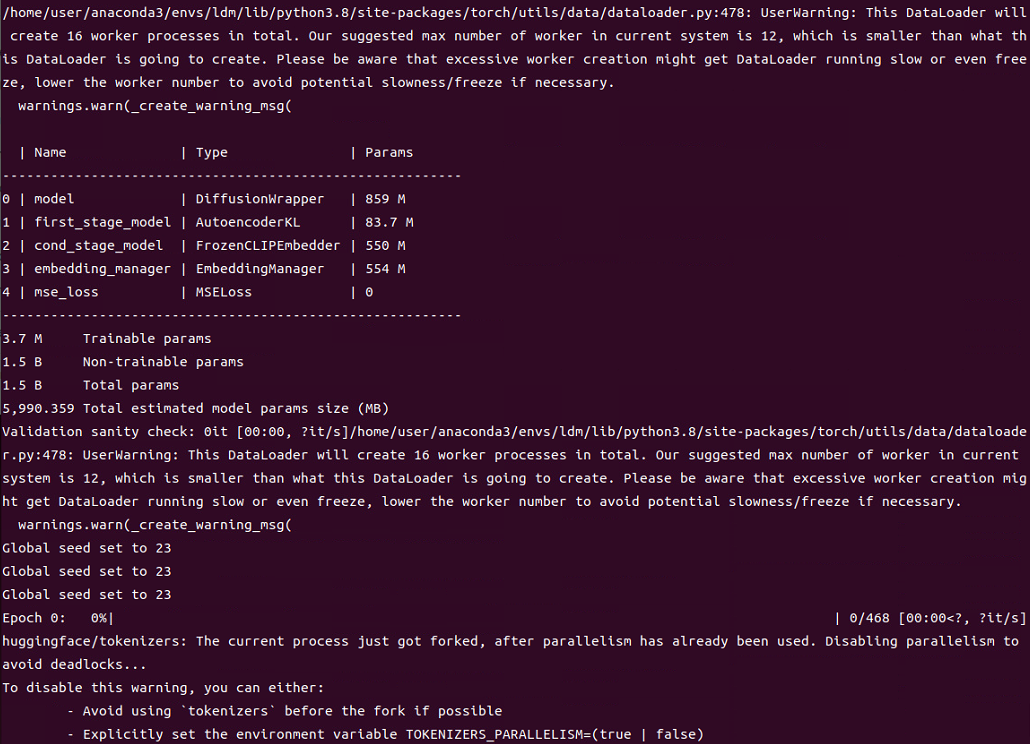
부족한 메모리에서 용쓰는 건 포기하고 기존에 테스트로 돌렸을 때 구현됐던 그 컴퓨터에서 다시 학습을 시작했다. style을 반영하고 있는 embedding file을 학습을 통해 만들어야 해서 학습을 시도하고 있다.
그런데 linux에서도 발견됐던 문제가 똑같이 windows에서도 발견됐다.
Traceback (most recent call last):
File "main.py", line 782, in <module>
trainer.test(model, data)
File "C:\Users\user\anaconda3\envs\ldm\lib\site-packages\pytorch_lightning\trainer\trainer.py", line 911, in test
return self._call_and_handle_interrupt(self._test_impl, model, dataloaders, ckpt_path, verbose, datamodule)
File "C:\Users\user\anaconda3\envs\ldm\lib\site-packages\pytorch_lightning\trainer\trainer.py", line 685, in _call_and_handle_interrupt
return trainer_fn(*args, **kwargs)
File "C:\Users\user\anaconda3\envs\ldm\lib\site-packages\pytorch_lightning\trainer\trainer.py", line 954, in _test_impl
results = self._run(model, ckpt_path=self.tested_ckpt_path)
File "C:\Users\user\anaconda3\envs\ldm\lib\site-packages\pytorch_lightning\trainer\trainer.py", line 1128, in _run
verify_loop_configurations(self)
File "C:\Users\user\anaconda3\envs\ldm\lib\site-packages\pytorch_lightning\trainer\configuration_validator.py", line 42, in verify_loop_configurations
verify_eval_loop_configuration(trainer, model, "test")
File "C:\Users\user\anaconda3\envs\ldm\lib\site-packages\pytorch_lightning\trainer\configuration_validator.py", line 186, in verify_eval_loop_configuration
raise MisconfigurationException(f"No {loader_name}() method defined to run Trainer.{trainer_method}.")
pytorch_lightning.utilities.exceptions.MisconfigurationException: No test_dataloader() method defined to run Trainer.test
pytorch-lightning 버전 문제였던 것 같은데 pytorch-lightning git에 issue로 문제를 해결하고 버전을 올려보라는 이야기가 있어서 최신걸로 업그레이드 했는데 또 다른 trainer 에서 충돌이 나서 다시 되돌리고..
1.7.7로 바꿨다가 1.6.5로 바꿨다가 했는데 전보다는 학습이 진행되더니 결국 똑같은 오류가 나서 결국 기본 environment 에 있던 1.5.9로 다시 바꿨다.
https://github.com/Lightning-AI/pytorch-lightning/issues/1720
https://github.com/Lightning-AI/pytorch-lightning/discussions/11437
교수님 해당 과제에서 요구하는 게 style transfer인데 일단 dreambooth로도 실행을 해보라고 하셔서 dreambooth도 한 번 사용해봤다.
dreambooth 설치기 : https://2ndyoung.tistory.com/172
2023.11.13~
'Daily life > Development vlog' 카테고리의 다른 글
| Dreambooth 설치기(Stable diffusion webui) (0) | 2023.11.30 |
|---|---|
| [랩세미나] 이미지 처리 트렌드 및 multi-degradation learning (0) | 2023.11.08 |
| 2023 졸업작품 VITON-HD custom.py (0) | 2023.10.19 |
| 이진 분류 pytorch (0) | 2023.08.01 |
| [210412]자바스크립트 프로그래밍 입문(한빛) 6장 연습문제 풀이 (0) | 2022.01.06 |


