
Bamboo is coming
[랩세미나] 이미지 처리 트렌드 및 multi-degradation learning 본문
Daily life/Development vlog
[랩세미나] 이미지 처리 트렌드 및 multi-degradation learning
twenty 2023. 11. 8. 17:061. Ingredient-oriented Multi-Degradation Learning for Image Restoration
- all-in-one fashion : 여러 저하(degradation) 현상을 하나의 모델로 처리하는 방식
- Meta prior learning module : prior-oriented degradation representation과 principle-oriented degradation operation의 결합 과정, prior embeddings과 corrupted features를 입력으로 받아 분류하고(prior-oriented) 이를 다시 물리학적 계산(principle-oriented)을 거치는 형태이다.
- 전체 모델 구조,Ingredients-oriented Degradation Reformulation framework (IDR) :
- Stage1(task-oriented knowledge collection) - learnable PCA - Stage2(Ingregients-oriented knowledge integration)
- Stage1: Task 특징별 일반화된 성능
- Stage2: Ingredient(Task hub-> ingredient hub:learning PCA 사용)
- Output: Ingredient
- Stage1(task-oriented knowledge collection) - learnable PCA - Stage2(Ingregients-oriented knowledge integration)
- TSNE 시각화: 딥러닝에서 여러 차원으로 모여있는 특징을 사람이 볼 수 있는 2,3차원으로 변환시키는 시각화 툴. feature는 랜덤으로 선택하고 이를 한 점에 모이게 만든다. 거리가 중요한 것이 아니라 모여있음을 보여주는 것이 특징을 잘 뽑았다는 것에 의미가 있음
- T-SNE(티스토리 https://gaussian37.github.io/ml-concept-t_sne/)
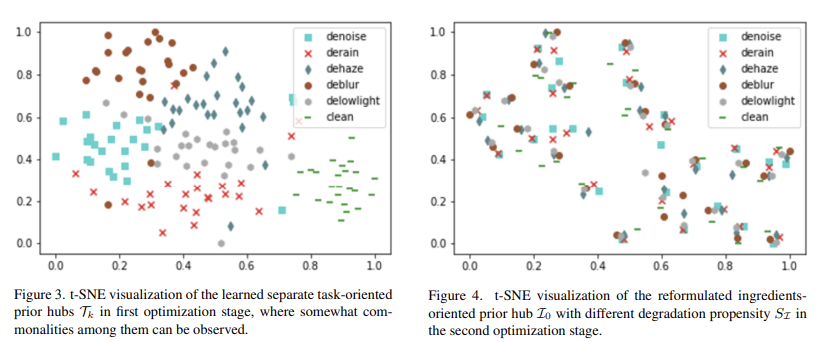
t-SNE 시각화, clean한 이미지 역시 일반화시켜서 특징을 만들어낸다. - restore image에서 L1 Loss만 사용할 경우 평균 때문에 blury한 결과가 추출된다.
- Common Representation: 이는 일반적으로 단일 데이터 유형(예: 이미지) 내에서 공통적으로 사용되는 특징이나 패턴을 나타내는 방식입니다. 예를 들어, 여러 이미지에서 공통적으로 나타나는 특징을 추출하여 이미지를 분류하거나 인식하는 데 사용됩니다. 이 표현은 해당 데이터 유형 내에서의 일반화를 목적으로 하며, 다양한 상황이나 조건에서도 유사한 방식으로 데이터를 인식할 수 있게 합니다.
- learning PCA ??
2. Is Transformer Really Better than ConvNet?
- 이미지 처리 트렌드 발표

- 2021 - Normalization Free ResNet(NF-ResNet)
- 2022 - Vision Transformer(VIT)
- - Swin Transformer : CNN과 결합한 VIT,
- - NLP에 비하여 visual domain에 낮은 성능을 가지는 transformer의 단점을 개선한 모델
- - hierarchial 구조와 shifted window 기법을 사용했고 latency(속도)면에서도 크게 발전함
- - Various Downstream Task : downstream task란 최종적으로 하고자 하는 작업,
- upstream은 먼저 해결해야 할 작업
- 2023 - ConvNeXt: ResNet50을 base로 hierarchical Transformer를 CNN으로 modernize하여 점차 성능을 높임
- - Fast Vit,A Fast Hybrid Vision Transformer using Structural Reparameterization:
- - Reparameterization을 이용해서 미분이 가능하도록 수식을 변경하는 개념
- - VanillaNet, the power of Minimalism in Deep Learning: 간단한 신경망 조합으로도 다른 모델과 비슷한 성능 낼 수 있음. activation function stacking(계산 비용 줄임), deep training strategy(conv layer 2개로 시간 줄임)사용
- - NF-ResNet: 2021년 업그레이드 버전
- inductive bias:
- VIT가 CNN 모델인 resnet을 능가하긴 했지만 inductive bias가 없어서 vision task에 아쉬움이 있었다.
- 참고로 Vanilla 라는 뜻은 without any customization 이라는 의미를 가지고 있습니다. default, ordinary, basic의 의미
출처: https://eehoeskrap.tistory.com/719 [Enough is not enough:티스토리] - BN의 단점을 개선한 instance norm, group norm, elimination 등 residual brunch를 근사화하는 작업이 있었음
- NF weighted standardization은 배치 사이즈가 커질수록 성능이 약했다.
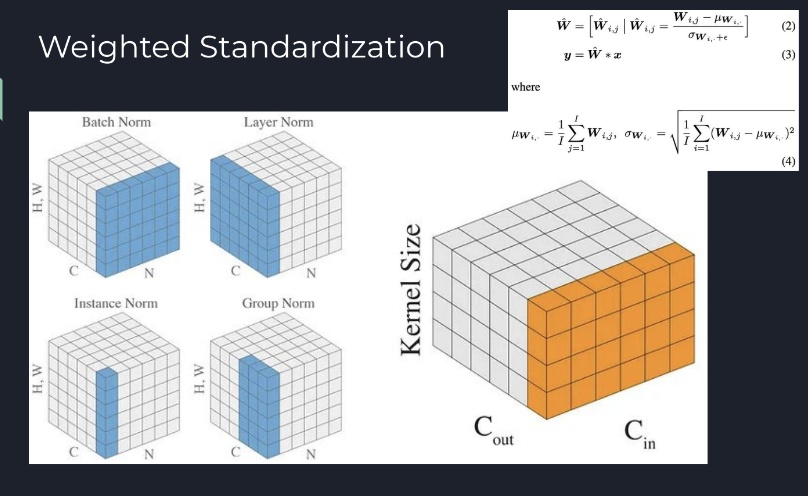
Gradient Clipping(2013)+NF+ResNet으로 SOTA 달성
[논문리뷰] ConvNext (https://americanoisice.tistory.com/121) (https://blog.kubwa.co.kr/%EB%85%BC%EB%AC%B8%EB%A6%AC%EB%B7%B0-a-convnet-for-the-2020s-9b45ac666d04)
'Daily life > Development vlog' 카테고리의 다른 글
| Dreambooth 설치기(Stable diffusion webui) (0) | 2023.11.30 |
|---|---|
| InST git 설치기(InST 모델 설명 및 실행기) (0) | 2023.11.21 |
| 2023 졸업작품 VITON-HD custom.py (0) | 2023.10.19 |
| 이진 분류 pytorch (0) | 2023.08.01 |
| [210412]자바스크립트 프로그래밍 입문(한빛) 6장 연습문제 풀이 (0) | 2022.01.06 |
'Daily life/Development vlog' Related Articles
more



Comments