
Bamboo is coming
Stanford CS231N 1강, 2강(Image classifier, Linear classifier) 본문
1강
vision의 역사 및 소개
2강
Image Classifier
image를 넣고 label을 받는 이미지 분류기
이미지 자체의 픽셀값으로 분류를 한다.
Nearest Negibor Classifier
머신러닝 알고리즘(SVM, K-means clustering, Decision tree, K-Nearest Neighbor)

거리 계산 방식

L1 distance는 맨하탄 거리라고도 불리며 각 데이터의 차를 절댓값을 씌운 값을 의미한다.
테스트 이미지와 트레이닝 이미지의 각각 원소별로 (pixel wise, elemental wise) 계산을 해서 행렬의 전체 합을 내어 테스트 이미지와 트레이닝 이미지의 거리를 구한다.

Q. 트레이닝 데이터의 크기에 따른 분류 스피드는?
A. 선형적
NN = 트레이닝 데이터 수가 늘어날 수록 분류 작업의 수가 늘어난다. 메모리 상에 트레이닝 이미지와 레이블을 모두 올려놓고 거리를 계산해야하기 때문에 그만큼 계산량이 많아짐(분류량이 많아짐).
이론적으로는 주위 K개만 비교하면 되지만 비교 대상이라는 것이 이미지에 있어서는 불명확하기 때문에 새로운 데이터 포인트와 훈련 데이터 셋 내의 모든 데이터 포인트 간의 거리를 계산해야 하고 계산된 거리를 정렬하여 가장 가까운 K개의 이웃을 식별해야 한다.
트레이닝 속도, 테스트 속도를 비교했을 때 테스트 속도가 더욱 중요한데 NN은 기존 데이터를 저장하고 있다가 범주에 맞게 분류를 하는 방식으로 traing, test 동일하게 데이터 크기가가 커지면 커질 수록 시간이 오래걸린다.
CNN = 트레이닝 속도는 오래 걸리지만 테스트 속도는 모두 동일하다.
Hyperparameter(하이퍼파라미터)
손실함수(Loss Functions), MAE, MSE, L1, L2, cross entropy

L1, L2 계산은 하이퍼파라미터로 선택사항이다. 여러가지를 테스트 해 본 후 선택하는 것이 좋다.

일반적으로 K-Nearest Neigher가 더 성능이 좋은 것으로 알려져 있다.
5-NN은 더 부드러운 곡선을 그림 -> 과적합 방지 가능
Q. training dataset으로 분류를 하게 되면 정확도는?
A. 100%
이미 학습된 데이터를 다시 분류를 하기 때문에 레이블이 주어진 값에 대해 자기 자신과 비교하는 셈이 된다.
유클리디언을 쓰나, 맨하탄을 쓰나 동일할 것.

Q2. K-nearset에 training data를 적용하면?
A. 상황에 따라 다르다. 1위는 정확할 수 있지만, 2,3위는 다수결에 따라 달라질 수 있다.

하이퍼파라미터는 각 문제마다 다르기 때문에 시도 후 변경해봐야 한다.
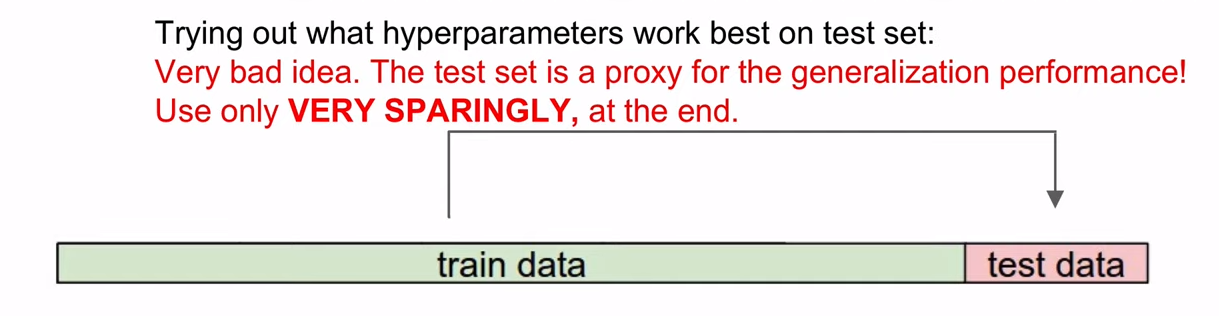
데이터 셋은 반드시 단 한번만 사용해야 한다.
정확성을 높이기 위함.
그래서 validation을 적용해야 하는데,
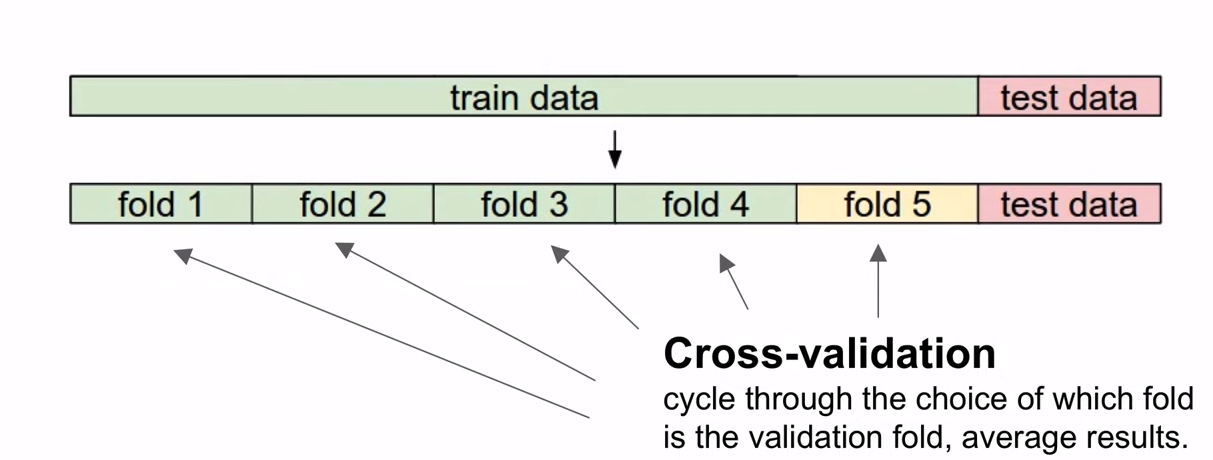
training dataset이 적다면 cross-validation을 활용해 볼수 있다.
1~4 - training/ 5- validation
2~5 - training/ 1- validation
이런식으로 반복해 나감.
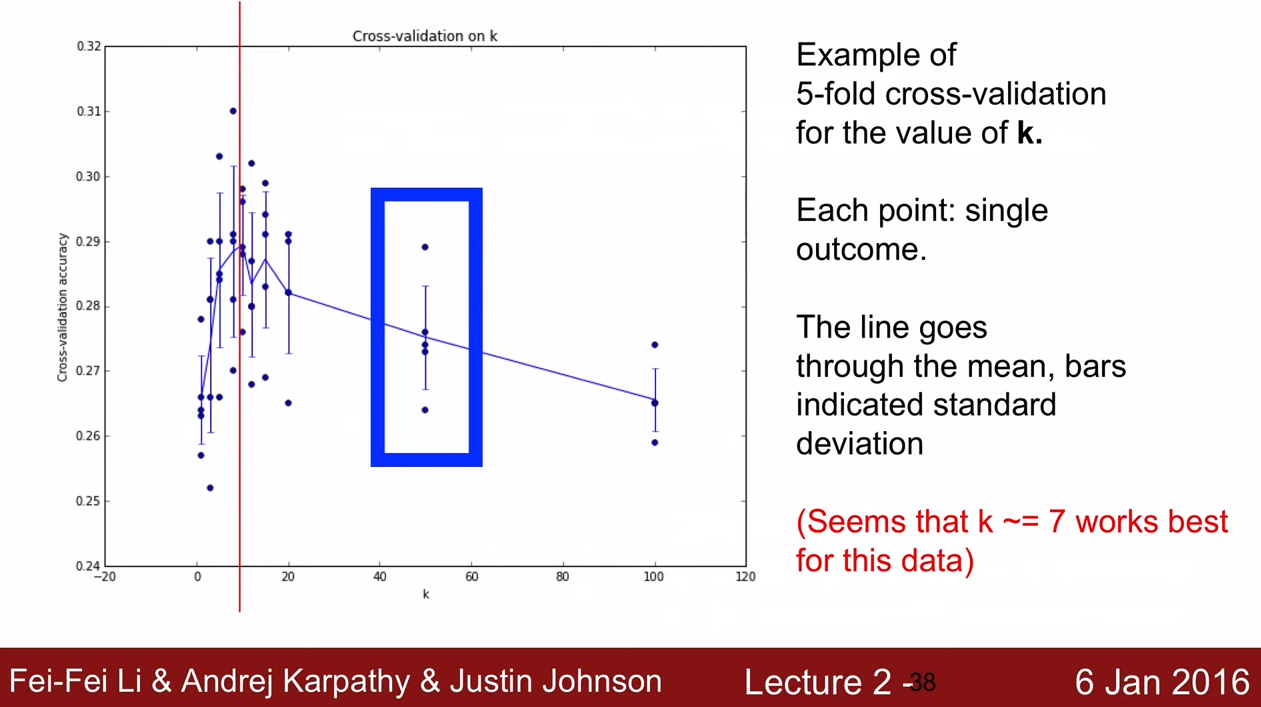
K-fold cross-validation의 k값에 따른 그래프를 보여준다.
x축은 k값이고 y축은 accuracy로, 5개의 박스그래프를 그렸고 선은 평균을 의미한다.
평균은 7인 경우에 가장 큰 정확도를 보인다.

네 개의 이미지가 변형된 이미지임에도 불구하고 동일한 판단을 한다.
이런 이유로 NN은 현실에서 사용되지 않는다.

요약
Image Classification
- 레이블이 달린 트레이닝 셋을 주고 테스트 셋의 레이블을 예측한다.
- K-nearest Neighbor Classifier : 트레이닝 셋의 가까운 이미지를 기반으로 레이블을 예측
거리 측정 방법(L1, L2)와 분류 갯수(k)는 검증 데이터 셋을 이용하여 조정하는 하이퍼파라미터로 선택사항이다.
만약 데이터의 사이즈가 작다면 검증 데이터 셋으로 cross-validation을 사용할 수 있다.
파라미터의 최적화된 세트가 정해지면 테스트 데이터 셋은 단 한번만 사용해야 한다.
Linear Classification
전체 강의에서 가장 중요한 시작점이다.
주어진 이미지의 선형결합(Linear combination)을 바탕으로 분류를 수행한다.
이미지 캡셔닝이란
이미지에 대한 자연어 설명을 생성하는 작업

이미지 캡셔닝 네트워크의 구조

CNN으로 이미지의 특성을 식별하고 추출하여 분류하고 CNN 특성을 기반으로 RNN으로 문장을 만들어내는 구조이다.
Parametric approach
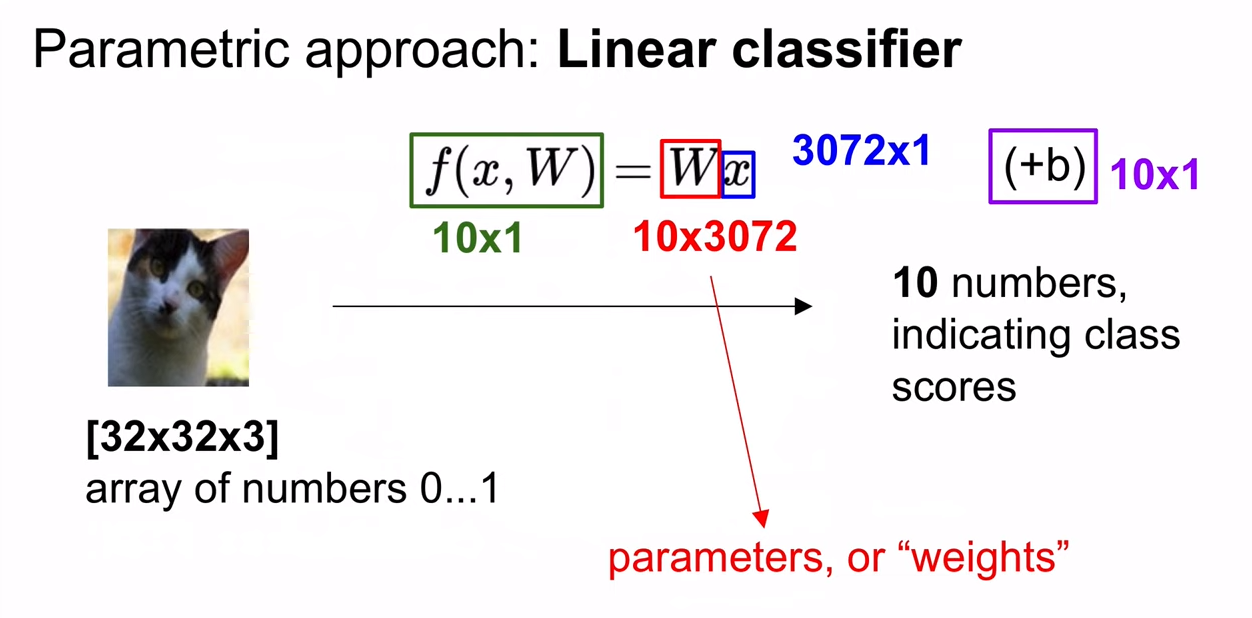
Weight - Parameters
이미지가 인풋으로 입력되었을때 어떤 클래스에 속하는지 구분해주는 w
weight 는 우리가 직접 만들어주어야 하는 부분(크기나 초깃값)
이 부분을 parametric approach라고 한다.
Nearst Neighbor - non parametric approach
Linear classification의 구조

Q. Linear Classifier를 설명하면
A. 이미지 내에 모든 픽셀값을 가중치와 곱한 것의 합
Just a weighted sum of all the pixel values in the image
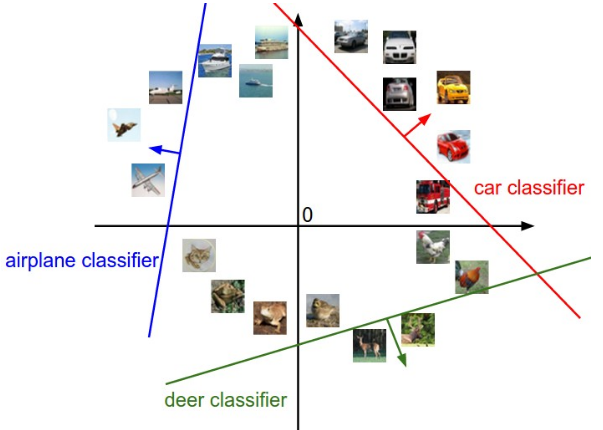
각각 다른 공간에 있는 컬러를 카운팅한 것.
Counting a color at different spatial position.

horse의 경우 왼쪽, 오른쪽을 나타내는 말을 모두 표현하고 있고
car는 빨간색의 차량이 많았기 때문에 가중치 맵이 빨간색을 주로 나타낸다.
classifier를 분류하는 방법으로는 공간이 있다.
Q2. linear classifier가 분류하기 힘든 데이터셋은 어떤 것이 될까.
A. 정반대의 색상을 가진 이미지 (개구리 초록색 -> 갈색)
Texture가 다르지만 색상이 같은 경우

지금까지는 linear classifier의 score function을 계산함.
점수에 따라 loss function을 정의해야하는데 score가 어느정도 좋고 나쁜지를 정리한 것을 의미한다.
이미지 -> score function -> loss function -> score -> loss
다음 시간에는 score function에 대해 배워본다.
CS231n Lecture note: Linear Classification (Support Vector Machine, softmax)
'참고 도서' 카테고리의 다른 글
| 안녕 트랜스포머 (0) | 2023.09.23 |
|---|---|
| Stanford CS231n 3강 (Loss Functions and Optimization) (0) | 2023.09.13 |
| 한땀한땀 딥러닝 컴퓨터 비전 백과사전 (0) | 2023.08.04 |
| Deep Learning Bible (0) | 2023.08.04 |
| 딥러닝 파이토치 교과서 (0) | 2023.08.01 |

