
Bamboo is coming
머신러닝 알고리즘(SVM, K-means clustering, Decision tree, K-Nearest Neighbor) 본문
인공지능 개념
머신러닝 알고리즘(SVM, K-means clustering, Decision tree, K-Nearest Neighbor)
twenty 2023. 8. 19. 00:03머신러닝 학습에서 사용되는 대표적인 알고리즘
- SVM
- K-means clustering
- Decision Tree
- K-Nearest Neighbor(KNN)
1. SVM(Support Vector Machine)
- 기계학습 분야 중 지도학습 알고리즘으로 이진 분류와 회귀에 주로 사용된다.
- 1995년 이후로 꾸준히 연구가 진행된 분야로 최근까지도 많이 사용될 뿐 아니라 높은 정확도를 보이고 있다.
- SVM의 핵심 개념은 margin과 hyperplane(초평면)이다.
- 이러한 SVM은 필기체 인식이나 이미지 분류 등에서 학습하는 데이터의 양을 줄일 수 있다.
- SVM에서 결정 경계와 가까운 샘플(셔포트 벡터)만이 결정 경계 형성에 영향을 미친다.
- 나머지 샘플들은 결정 경계에서 멀리 떨어져 있으므로 모델 학습의 기여하지 않는다.
- 즉, 확실한 샘플은 제외하고 애매한 샘플들만 학습에 사용해서 안정적인 예측을 할 수 있게 하고 모델을 단순하게 만들어 복잡도가 줄어든다.
1.1. Hyperplane
- hyperplane(초평면)은 고차원 공간을 나누는 결정 경계이다.
- d차원 공간에서 초평면은 d-1차원 객체이다.

- 사진에서 보면 왼쪽 2차원의 초평면은 1차원 직선, 오른쪽 3차원의 초평면은 2차원 평면이 되는 것이다.
- SVM에서 초평면은 $w . x+b=0$의 방정식으로 표현된다.
- w는 법선 벡터(직선 또는 평면의 방향), b는 바이어스 항
SVM의 목표는 두 클래스 간의 margin을 최대화하는 이 초평면을 찾는 것이다.
1.2. Margin
- margin은 두 클래스 간의 간격을 나타내며 초평면에서 가장 가까운 훈련 샘플까지의 거리로 정의된다.
- margin이 크면 일반화 성능이 좋아질 가능성이 높아진다.
- 마진이 크면 결정 경계 주변에 넓은 안정 영역이 생성되어 새로운 샘플에 대한 예측을 더 안정적으로 만들어준다.
- 마진을 최대화하면 모델이 더 단순해져서 복잡도가 줄어들고, 과적합을 방지하는 데 도움이 된다.
- 모호한 샘플의 영향을 감소시켜서 일반화 성능이 더 좋아지게 만든다.
- margin은 hard margin, soft margin으로 나뉜다.
- hard margin: 모든 샘플이 올바르게 분류되는 경우 사용된다. 이상치가 없어야 하며, 데이터가 선형적으로 완벽하게 분리되는 경우 적용
- soft margin: 일부 오분류를 허용하면서 마진을 최대화한다. 이는 이상치가 있는 경우나 선형적으로 완벽하게 분리할 수 없는 데이터에 사용된다.
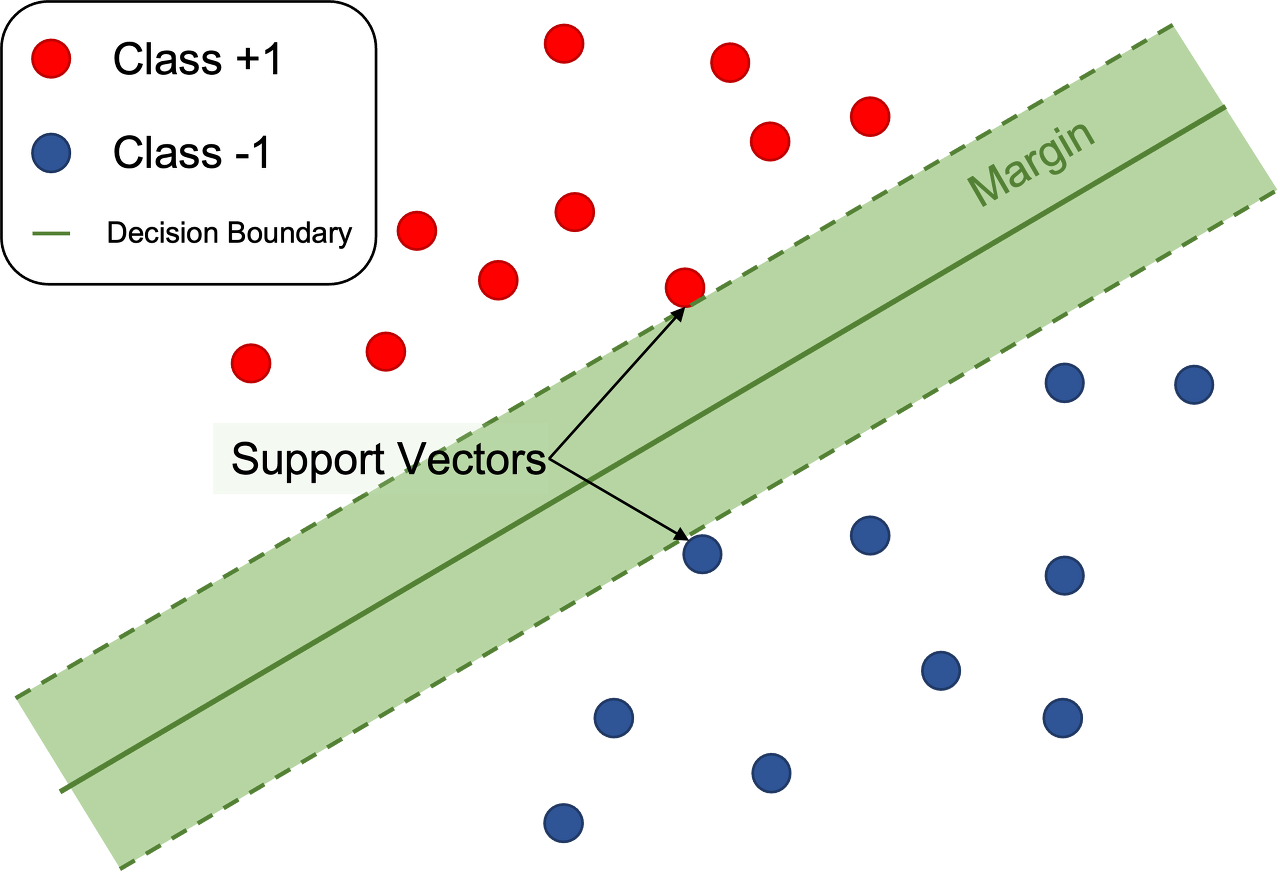

Support Vector는 초평면에 가장 가까운 훈련 샘플로 마진의 너비를 결정한다. 이 샘플이 초평면을 만드는 데에 support를 하기 때문에 서포트 벡터라고 불린다.
1.3. SVM의 작동 방식
- Hyperplane(초평면) 선택: 두 클래스 사이의 마진을 최대화하는 초평면을 찾는다.
- Classification(분류): 새로운 샘플이 주어지면, 해당 샘플이 초평면의 어느 쪽에 위치하는지 확인하여 분류
- Kernel Trick(커널 트릭): 비선형 분류 문제의 경우, 커널 함수를 사용하여 고차원 공간으로 매핑하고, 그 공간에서 초평면을 찾을 수 있다.
1.3.1. basis function/feature map
- 분류 문제에서 선형으로 샘플을 분류할 수 없을 때 input space(예,2차원)를 feature space(예,3차원)으로 변형시켜서 평면으로 구별할 수 있도록 하는 함수.
- 즉, 비선형 특징을 가지는 input space를 선형 특징을 가지는 feature space로 변환해주는 함수
1.3.2. Kernel

- SVM에서도 비선형문제를 선형화할 수 있는 문제를 풀 때 feature map을 적용할 수 있는데 이 때 feature map를 찾는 것이 어렵고, feature map을 정의한 후에도 문제를 풀기 위한 연산량이 너무 많아서 kernel이 고안되었다.
- Kernel은 고차원 변환 + 내적 연산량 문제를 동시에 해결하기 위해 사용된다.
- 이미 증명된 다양한 Kernel이 있어서 내적을 계산할 수 있는 kernel을 사용하면 된다. (단, Mercer's Theorem을 만족하는 Kernel이어야 함)
- 여기서 Kernel은 결국 두 벡터의 내적이며 기하학적으로 cosine 유사도를 의미하기 때문에 similarity function이라고도 불린다.
- $K(x_i,x_j)=x_i,x_j$의 유사도
그리고 이 함수들을 이용한 Linear technique를 Kernel Trick이라고 한다.
1.4. 동작 예시
$w_1 . x_1 + w_2 . x_2+b=0$
- $w_1,w_2$는 직선의 방향을 결정하는 벡터.
- $x_1, x_2$는 각각 데이터 포인트의 두 특성.
- b는 y절편으로, 직선이 y축과 만나는 점.
1.4.1. 초평면의 동작
- 결정 경계: 위의 방정식은 2차원 공간에서 두 클래스를 나누는 직선을 형성합니다. 이 직선을 기준으로 한 쪽은 한 클래스, 다른 쪽은 다른 클래스로 분류된다.
- 샘플 분류: 새로운 샘플 x에 대해 위의 방정식을 계산하면, 결과가 0보다 크면 한 클래스에, 0보다 작으면 다른 클래스에 속하게 된다.
- $w_1 . x_1 + w_2 . x_2+b>0$: 클래스 1에 속함
- $w_1 . x_1 + w_2 . x_2+b<0$: 클래스 2에 속함
- 마진 최적화: SVM은 이 직선을 가능한 한 두 클래스 사이의 가장 가까운 포인트로부터 멀리 떨어지게 하려고 한다. 이를 통해 더 견고하고 일반화된 결정 경계를 얻을 수 있다.
2. K-means Clustering(K-means 군집화)
- K-means 군집화는 비지도 학습의 군집화 중에서도 분할 기반(partition-based)의 군집화의 속하는 방법이며, 가장 간단한 비지도 학습 알고리즘 중 하나이다.
- 주어진 데이터를 k개의 클러스터로 묶는 알고리즘으로, 각 클러스터와 거리 차이 분산을 최소화하는 방식으로 동작한다.


2.1. K-means Clustering 동작 방식
- 총 n개의 데이터를 학습할 경우 n보다 작거나 같은 k를 결정한 후, 초기의 중심점을 k개 설정함.
- 모든 학습 데이터는 k개의 중심점까지의 거리를 각각 계산한 후에 가장 가까운 중심점을 자신이 속한 군집(cluster)의 중심점이라고 저장함.
- 각 군집에 속한 데이터에 저장된 중심점 좌표값들의 평균을 구한 뒤 이를 바탕으로 해당 군집의 새로운 중심점을 설정함.
- 새롭게 설정된 중심점을 가지고 2단계와 3단계를 다시 반복함.
- 모든 학습 데이터가 자신이 속한 군집을 변경하지 않는 경우 학습을 완료함.
2.1.1. 초기 중심점 선택 기법(초기화 기법)
- 무작위 분할
- 데이터들을 임의의 클러스터에 배당한 후, 각 클러스터에 배당된 점들의 평균값을 초기$\mu _i$(i번째 클러스터의 중심점)로 설정한다.
- 다른 기법들과 달리 데이터 순서에 독립적이다.
- 무작위 분할의 경우 초기 클러스터가 각 데이터들에 대해 갯수가 고르게 분포되기 때문에 각 초기 클러스터의 무게 중심들이 데이터 집합 중심에 가깝게 위치하는 경향을 띈다.
- K-조화 평균이나 퍼지 K-평균 알고리즘에서 선호됨.
- Forgy
- 1965년 Forgy에 의해 고안되었으며 현재 주로 쓰이는 초기화 기법 중 하나이다.
- 데이터 집합으로부터 임의의 k개의 데이터를 선택하여 각 클러스터의 초기$\mu _i$(i번째 클러스터의 중심점)로 설정한다.
- 무작위 분할 기법과 마찬가지로 Forgy 알고리즘은 데이터 순서에 대해 독립적이다.
- 이 알고리즘은 초기 클러스터가 임의의 k개의 점들에 의해 설정되기 때문에 각 클러스터의 무게 중심이 중심으로부터 퍼져있는 경향을 띈다.
- EM(기댓값 최대화) 알고리즘이나 표준 K-평균 알고리즘에서 선호됨
- K-means++
- k-means 알고리즘의 초기값을 선택하는 알고리즘으로 중심점 간에 거리가 멀도록 초기 중심점을 선택한다.
- k-means++ 알고리즘은 초기값을 선택하기 위해 추가적인 시간을 필요로 하지만 이후 선택된 초기값은 k-means clustering 알고리즘이 $O(logk)$의 시간동안 최적 k-평균 해를 찾는 것을 보장한다.
2.2. 장점
- K-means 군집화는 알고리즘의 개념이 매우 직관적이다.
- 학습을 위해 수행해야 할 데이터의 계산의 양이 매우 적다.
2.3. 단점
- 모양이 구형(spherical)이 아닌 군집에 대해서는 정확도가 떨어지고, 동떨어져 있는 데이터 즉 이상값(outlier)에 매우 민감하다
- 클러스터 개수 K값을 입력 파라미터로 지정해주어야 하는데, 맨 처음에 결정한 군집의 개수인 k에 따라 결과값이 완전히 달라지는 경우도 발생한다.
- 알고리즘의 에러 수렴이 전역 최솟값이 아닌 지역 최솟값으로 수렴할 가능성이 있다.
- 즉, 비용 함수의 함수 공간에서 최적화를 시행할 때, 에러가 줄어드는 방향으로 최적해를 찾아가게 되는데, 전역이 아닌 지역 최솟값에 도달해도 알고리즘의 수렴 조건을 만족하게 되므로 더 이상 최적화를 진행하지 않게 된다. 따라서, 사용자가 기대한 결과를 얻지 못하게 되는 것이다.


- 원래 k=4이라고 하면 한 클러스터에 여러 값이 군집되어 있거나 클러스터들이 군집되지 못하는 경향을 띈다.
2.4. 복잡도
k-평균 알고리즘의 계산 복잡도에 크게 영향을 미치는 요소 두가지는 유클리드 공간 d와 클러스터의 수 k이다.
클러스터의 수가 작더라도, 일반적인 유클리드 공간 d에서 k-평균 알고리즘의 최적 해를 찾는 것은 NP-난해이다.
반대로 낮은 차원의 유클리드 공간일지라도, k개의 클러스터에 대해 최적 해를 찾는 것 또한 NP-난해이다.
2.5. 활용분야
- 시장 분석, 이미지 작업, 지질 통계학, 천문학 등 광범위한 분야에서 활용되고 있다.
- 이미지 분석
- 각 픽셀에 어떤 레이블을 붙여줌으로써 비슷한 성질을 가진 픽셀 끼리 같은 레이블을 가지게 하는 것이다.
- 이미지 분할의 목표는 주어진 이미지를 단순화하고 이미지 표현 방식을 단순화하여 이미지를 좀 더 분석하기 편한 형태로 만드는 것이다.
- 특히 다른 알고리즘을 수행하기 전에 학습 데이터를 전처리(pre-processing)하는 용도로도 많이 사용되고 있다.
- 특성 엔지니어링: 데이터의 구조를 파악하며 여러 그룹으로 나눌 수 있고 이것으로 새로운 특성을 생성할 수 있다.
- 노이즈 제거와 이상치 탐지: 이상값에 민감한 특성상 이를 미리 제거하거나 따로 처리하여 모델의 성능을 향상시킬 수 있다.
- 차원 축소: 대규모 데이터셋에서 군집 중심으로 데이터를 매핑하면 데이터의 차원을 줄이고 계산 효율성을 높일 수 있다.
- 초기화와 레이블링 도움: 비지도 학습으로 지도 학습 작업을 돕기 위해 초기 레이블을 제공하거나 모델 초기화에 도움이 될 수 있다.
3. Decision tree(의사 결정 트리)
- 지도학습 알고리즘 중 하나로 귀납적 추론을 기반으로 하여 데이터 사이에 존재하는 패턴을 시각적이고 명시적인 방법으로 보여주는 알고리즘이다.
- 지도 학습의 분류 모델이나 회귀 모델 둘 다에 적용할 수 있다.
- 의사 결정 트리의 기본 개념은 질문을 던져 답을 얻음으로써 그 대상을 좁혀나가는 일종의 ‘스무고개’ 놀이와 비슷한 개념이다. 의사 결정 트리의 분석 결과는 ‘조건 A이고 조건 B이면 결과는 C’라는 형태로 표현되므로 쉽게 이해할 수 있다.
- 따라서 다른 알고리즘에 비해 쉽게 활용할 수 있는 장점을 가지고 있다.
- 결정 트리는 3가지 종류의 노드로 구성된다
- 결정 노드(decision node): 사각형으로 보통 표시함
- 기회 노드(chance node): 원으로 보통 표시함
- 종단 노드(end node): 삼각형으로 보통 표시함
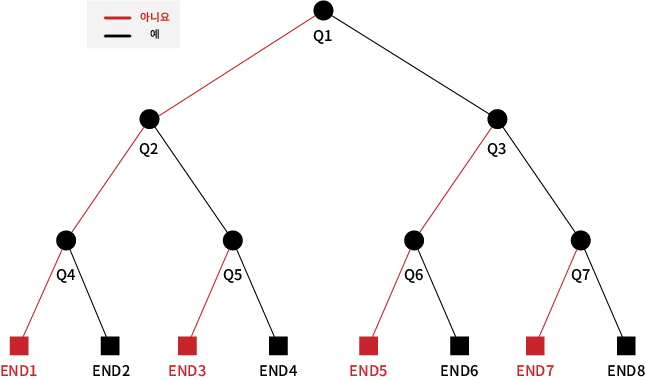
3.1. 작동 방식
- 목표 속성(target attribute)과 이와 관계가 있는 후보 속성(candidate attribute)들을 선택함.
- 데이터를 분석하는 목적과 자료 구조에 따라 적절한 분리 기준과 정지 규칙을 정하여 트리 구조를 작성함.
- 정지 규칙이란 더 이상 분리가 일어나지 않고 현재 노드가 잎 노드(leaf node)가 되도록 하는 여러 규칙들을 의미한다.
- 완성된 트리 구조에서 정확도를 떨어뜨리는 속성은 제거함.(가지치기, pruning)
3.2. 활용 분야
환자의 과거 진료 기록을 토대로 증상을 유추하거나 대출을 위한 신용평가, 고객의 소비 행동 예측 등 다양한 분야에서 활용되고 있다.
4. K-Nearest Neighbor(KNN, K-최근접 이웃)
- 지도 학습 알고리즘 중 하나로 어떤 데이터가 주어지면 그 주변(이웃)의 데이터를 살펴본 뒤 더 많은 데이터가 포함되어 있는 범주로 분류하는 방식이다.
- 모델을 별도로 구축하지 않는다는 뜻으로 게으른 모델(Lazy model)이라고 부른다.
- 인스턴스 기반 학습 또는 게으른 학습의 일종으로, 학습 단계에서 별도의 모델을 학습시키지 않고 학습 데이터 자체를 메모리에 저장한다.
- 분류 작업을 수행할 때 주어진 데이터 포인트와 가장 가까운 'K'개의 이웃 데이터 포인트를 찾아, 그 이웃들의 범주 중 가장 흔한 범주로 데이터 포인트를 분류한다.
- 여기서 가까운 k개의 이웃 데이터 포인트는 거리 측정(L1, L2)의 방식을 사용한다.
- K는 주위 살펴볼 이웃의 갯수, 즉 탐색할 데이터를 의미한다.
- K=1일때 알고리즘은 가장 가까운 이웃의 범주 또는 값에 따라 데이터 포인트틀 분류 또는 예측한다.
- K=3일때 알고리즘은 가장 가까운 세 개의 이웃을 참조하고, 분류 문제의 경우 다수결 방식으로, 회귀 문제의 경우 평균값을 사용하여 데이터 포인트를 분류 또는 예측한다.
- 장점
- 훈련이 따로 필요없고 훈련 데이터를 저장하기만 하면 된다.
- SVM이나 선형회귀보다 빠르다.
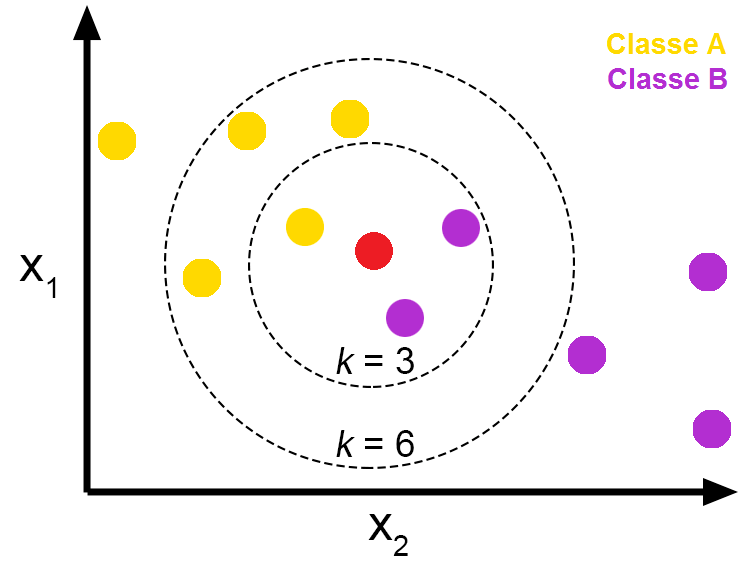
4.1. 거리계산
4.1.1. 유클리드 거리(Euclidean Distance)
- 일반적으로 점과 점 사이를 구하는 방법
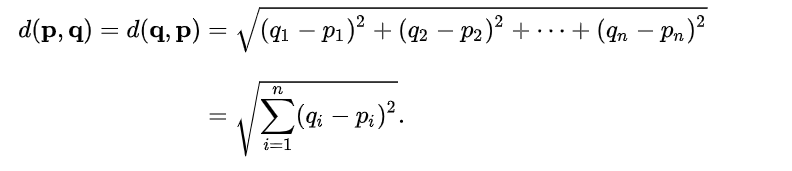
4.1.2. 맨하탄 거리(Manhattan Distance)
- 점과 점 사이의 직선거리가 아니라 x축, y축을 따라 간 거리를 의미한다.
- 맨하탄 시내에 빌딩이 많아 위치를 이동하기 위해서는 격자 모양의 길을 따라 가야한다고 해서 생겨난 말이다.
- 빌딩을 굽이굽이 돌아서 가나, 큰 길로 직선으로 가나 거리는 동일하다.
- L1 norm으로 부르기도 한다.
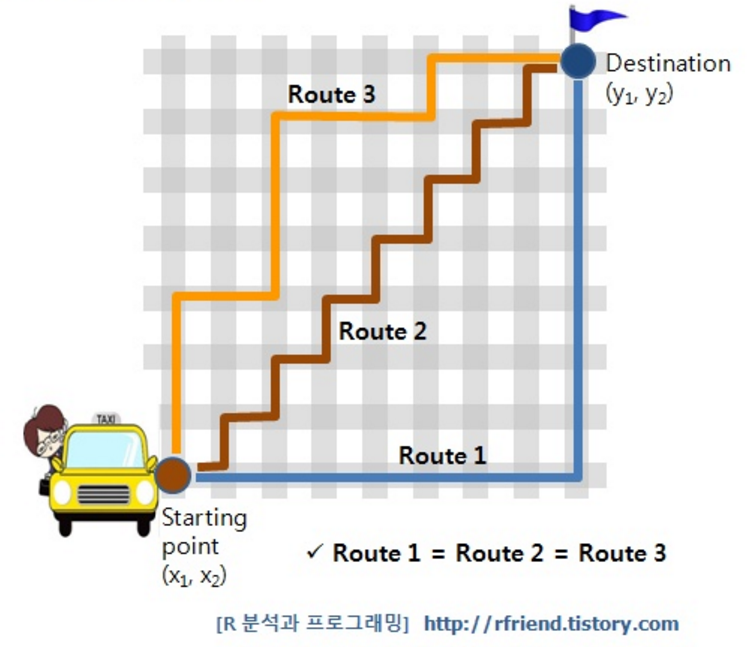
참고
'인공지능 개념' 카테고리의 다른 글
| CNN(Convolution Neural Network) (0) | 2023.08.23 |
|---|---|
| [GPT] GAN(Generate Adversarial Networks) (0) | 2023.08.22 |
| Explainable AI(XAI) - Grad-CAM, LIME, disconvolution (0) | 2023.08.06 |
| weakly supervised (0) | 2023.08.04 |
| 데이터 세트 분리 Data set split (0) | 2023.08.04 |
'인공지능 개념' Related Articles
more


Comments