
Bamboo is coming
안녕 트랜스포머 본문
## 어텐션
어텐션은 Query, Key, Value의 연산인데 질의문(Query)와 매칭대상(Key)의 유사도를 계산하여 weight를 곱한 후 값(Value)를 다시 곱해 유사도에 따른 값의 가중치를 가질 수 있도록 만든것이다.
셀프어텐션은 Q,K,V값이 모두 동일해 자기 자신으로부터의 유사 가중치를 가지는 것을 의미한다.
하나의 시퀀스에서 첫 번째 토큰과 마지막 토큰 간의 관계를 연산하여 서로 멀리 떨어져 있는 단어들간의 의존성을 고려할 수 있도록 설계된 것이다.
** 2차원의 행렬 곱 차원 일치
(M, N) x (N, P)
3차원
(n, m, k) x (n, k, p) 행렬 A의 마지막 차원과 행렬 B의 두번째 차원
4차원
(b,n,m,k)X(b,n,k,m) 행렬 A의 마지막 차원과 행렬 B의 세번째 차원
## 트랜스포머
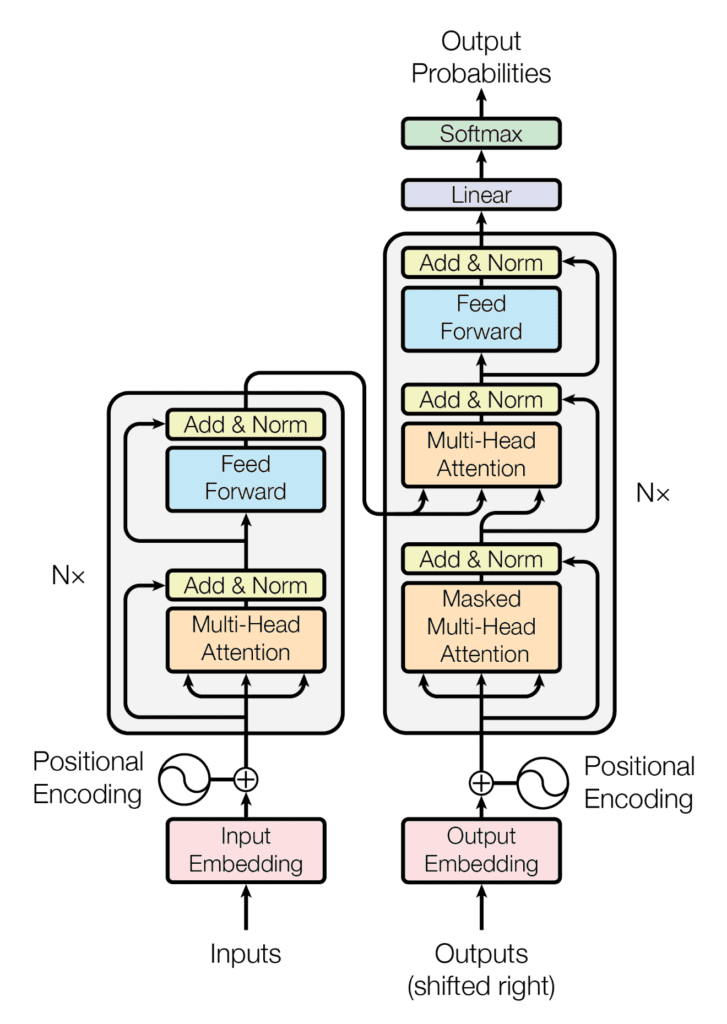
입력과 출력의 텍스트는 토크나이저를 이용해 토큰화한 후 각각의 토큰을 숫자로 매핑한다.
입력 토크나이저, 출력 토크나이저(역 토큰화)
인코더 디코더 형식으로 이루어져있고
인코더는 토큰화된 입력을 받아 self-attention - feed forward로 되어있는 레이어를 6번 통과한다. 다음 레이어의 입력은 통과한 인코더의 결과가 된다.
디코더는 feed forward - endocder/decoder attention - self attention 로 되어있는 서브레이어를 6번 통과하는데 매 서브레이어에는 인코더의 가장 마지막 출력을 입력과 디코더의 결과를 받아서 디코더를 진행시킨다.
그림에 나와 있는 멀티헤드 어텐션은 GPU 사용을 극대화 하기 위해서 하나의 입력값(토큰)을 N개로 쪼개서 각각 어텐션을 계산한다.
## BERT(Bidirectional Encoder Representations from Transformers)
2018년 10월에 구글이 발표한 언어 모델으로 레이블이 없는 데이터로부터 레이블을 스스로 생성해(self-supervised learning) 사전 학습을 진행해서 만들어진 pre-trained model 이다.
BERT 모델의 구조는
임베딩과 인코더로 되어있다.
1. 토큰화
BERT의 입력 데이터는 평문을 토큰화하는 것부터 시작한다. 토큰화를 수행하는 토크나이저는 wordpiece tokenizer 또는 sentencepiece tokenizer로 불린다. 더 이상 쪼갤 수 없는 유닛 단위로 쪼갠 후 인접하는 유닛끼리 합쳐가면서 토큰을 만든다. 워드피스 토크나이저를 사용하면 유사한 의미를 지닌 서브워드를 하나의 토큰으로 분리해서 사용할 수 있다.
BERT에서 토큰화를 수행하는 방식은 다음과 같습니다.
준비물 : 이미 훈련 데이터로부터 만들어진 단어 집합
1. 토큰이 단어 집합에 존재한다.
=> 해당 토큰을 분리하지 않는다.
2. 토큰이 단어 집합에 존재하지 않는다.
=> 해당 토큰을 서브워드로 분리한다.
=> 해당 토큰의 첫번째 서브워드를 제외한 나머지 서브워드들은 앞에 "##"를 붙인 것을 토큰으로 한다.
예를 들어 embeddings이라는 단어가 입력으로 들어왔을 때, BERT의 단어 집합에 해당 단어가 존재하지 않았다고 해봅시다. 만약, 서브워드 토크나이저가 아닌 토크나이저라면 여기서 OOV 문제가 발생합니다. 하지만 서브워드 토크나이저의 경우에는 해당 단어가 단어 집합에 존재하지 않았다고 해서, 서브워드 또한 존재하지 않는다는 의미는 아니므로 해당 단어를 더 쪼개려고 시도합니다. 만약, BERT의 단어 집합에 em, ##bed, ##ding, #s라는 서브 워드들이 존재한다면, embeddings는 em, ##bed, ##ding, #s로 분리됩니다. 여기서 ##은 이 서브워드들은 단어의 중간부터 등장하는 서브워드라는 것을 알려주기 위해 단어 집합 생성 시 표시해둔 기호입니다. 이런 표시가 있어야만 em, ##bed, ##ding, #s를 다시 손쉽게 embeddings로 복원할 수 있을 것입니다.
사전학습 방식
1. MLM(Masked Language Model)
빈칸채우기
토큰화 되어 들어오는 입력을 임의로 마스킹하고 마스킹된 값들을 맞추는 멀티 레이블 분류 문제이다.
원래의 문장을 마스킹한 후 학습하게 되므로 self-supervised learning이라고 한다.
입력 토큰 85% 무시
15% - 80% 마스킹
10% - 랜덤토큰 치환
10% - 처리 안함.
중간중간 섞인 랜덤 토큰+마스킹 토큰으로 예측을 수행한다.
https://wikidocs.net/images/page/115055/%EC%A0%84%EC%B2%B4%EB%8B%A8%EC%96%B4.PNG
마스킹 데이터 - 뭔지 맞추기
랜덤토큰 데이터 - 원래 뭐였는지 맞추기
처리 안한 데이터 - 원래 뭐였는지 맞추기(변경됐는지, 아닌지는 알지 못하는 상태기떄문에)
2. NSP(Next Sentence Prediction)
다음 문장 맞추기. 문맥관계인지 아닌지
입력은 두개의 문장을 받아서 문맥 관계인지 뒤에 올 말로 어울리는 지에 대한 내용을 학습하고 예측함.
## GPT(Generate Pre-Training)
OpenAI가 2018년 6월에 발표한 모델로 BERT보다 약 사 개월 일찍 발표됐다. 인코더를 이용한 BERT와 달리 디코더를 사용했다.
GPT는 주어진 단어를 기반으로 다음에 오는 단어를 맞추는 방식으로 전통적인 언어모델의 사전 학습 방식을 따른다.
Masked Self-Attention
주어진 토큰들로부터 다음 토큰을 예측할 때 어텐션이 적용되는데 이 때 반드시 주어진 토큰들로부터만 어텐션 가중치를 가져야한다.
양방향(Bidirectional, 문장 좌우)로 정보를 받아오는 BERT와 달리 단방향(unidirectional, 이미 등장한 문장)으로 정보를 가져온다.
그래서 아직 등장하지 않은 문장은 마스킹 처리해서 가중치를 0으로 만든다. 예측할 토큰 뒤쪽에 있는 토큰에는 매우 큰 음수를 V로 정해서 QK의 스코어에 매우 큰 음수인 V를 더해준다. 이 값을 softmax함수 처리하면 매우 큰 음수인 등장하지 않은 문장 부분에는 가중치가 0에 수렴하고 나머지 값들의 합은 1이 된다 .
## RoBERTa
Facebook에서 2019년 7월에 발표된 논문으로 Robustly Optimized BERT Approach 이다. 이 모델의 핵심은 BERT의 성능을 향상시키는 방법으로 구조는 동일하지만 MLM 데이터 처리 방법, NSP 처리 방법, 배치 사이즈, 토크나이저 변경등의 방법을 통해 몇몇 벤치마크 데이터셋 태스크에서 BERT의 성능을 뛰어 넘었다.
1. MLM -> 정적 또는 동적 마스킹 전량
원래 BERT에서는 데이터 전처리 과정에서 토큰들에 대한 마스킹은 하나에 대해서 하나의 마스킹만이 사용된다.
static - 그래서 학습 양을 늘리기 위해서 하나의 데이터에 마스킹을 서로 다르게 해줌으로써 서로 다른 10개의 데이터를 사용해서 MLM를 학습하게 된다.
dynamic - 모델에 입력으로 사용할 때마다 매번 새로운 마스킹을 하는 것이 Dynamic masking
static은 data augment의 개념으로 볼 수 있고 dynamic을 일반화 성능을 향상시킬 수 있을 것으로 보인다.
2. NSP -> 여러 종류의 문장 예측
text A - 아침에 일어났다. 이상하게 배가 아팠다.
text B - 오늘은 왠지 술을 한 잔 하고 싶다. 비도 오고 일도 잘 안 된다.
왠지 모르게 다 내려놓고 놀고 싶은 날이다.
- Segment pair + NSP
segment - 하나의 데이터에서 연속된 문장
”아침에 일어났다. 이상하게 배가 아팠다. / 오늘은 왠지 술을 한 잔 하고 싶다. 비도 오고 일도 잘 안 된다.“
- Sentence pair + NSP
Sentence - 문장 단위로의 NSP
“아침에 일어났다. / 이상하게 배가 아팠다.“
문장 전체 데이터 중에서 다음 문장을 예측하는 것이 아니라 문장을 두 개만 이용해서 NSP를 학습하기 때문에 토큰의 길이가 훨씬 적은 경우가 많다. 그래서 배치 사이즈를 증가시켜 한번에 데이터를 많이 학습한다. 이로 인해 하나의 배치에서 학습하는 토큰의 수를 다른 방법들과 비슷하게 만들어줄 수 있다.
- Full sentences (NO NSP)
”왠지 모르게 다 내려놓고 놀고 싶은 날이다. / 우와 엄마가 선물을 줬다.“
임의의 segment를 한 개 이상의 문단으로부터 가져와 길이가 512가 될 때까지 잇는다.
- Doc sentences
full sentences와 같은 방법인데 한 개의 문단으로부터만 데이터를 가져온다.
이도 한 문단의끝 지점 근처부터 샘플링될 경우 입력의 길이가 512보다 짧을 가능성이 높다.
이 역시 배치 사이즈를 증가시키고 데이터셋 크기도 키워서 충분한 개수의 토큰 수가 나올 수 있도록 수정한다.
## ALBERT(A Lite BERT)
2019년 7월에 Google Research 와 Toyota 가 연구해서 발표한 모델이다.
BERT의 모델 사이즈가 크다는 단점을 극복한 언어 모델이며, 모델 사이즈를 줄인 동시에 성능도 비슷하거나 높은 수준으로 끌어올렸다.
1. Factorized Embedding Parameterization
임베딩 파라미터를 줄여서 모델 사이즈를 줄이는 방법으로 임베딩 레이어를 만들 때 임베딩 사이즈(E)를 히든 사이즈(H)와 같게 뒀는데, H가 커질수록 E도 같이 커지게 되는 구조이다. H는 Context-dependent한 피처를 학습하기 위함이고 E는 Context-independent한 피처를 학습하기 위함이다. 따라서 H를 크게 갖는 것은 좋지만 그로 인해 E가 필요 이상으로 커지게 된다. 문장에 독립적인 피처는 크게 학습할 필요가 없으므로 E와 H를 굳이 같은 값으로 묶어버릴 필요가 없다는 것이다.
BERT에서 임베딩 레이어의 파라미터 크기는 V E이다. 그런데 BERT에서는 E=H이기 때문에 임베딩 레이어의 파라미터 크기는 v H 와 같다.
ALBERT에서는 VE로 임베딩하고 임베딩된 E 차원을 H 사이즈로 다시 변형한다. 이 때 E는 H보다 훨씬 작게 설정한다. 논문에서는 이 내용을 수학적으로 VH를 분해(decomposition)해서 VE와 EH로 만든다고 설명하고 있다.
이 처리로 인하여 임베딩 레이어 파라미터 개수는 BERT에 비해 약 80% 정도 감소했다.
2. Cross-layer Parameter Sharing
BERT에서 self-attention을 계산해서 H 차원의 결괏값을 만들어내는 bertLayer 블록을 12번 반복한다. ALBERT에서는 이 구조의 블록을 한 번만 만들되, 사용 시에는 ㅕㄹ괏값을 다시 입력값으로 집어넣는 과정을 12번 반복해서 결과적으로 모델 사이즈를 1/12로 줄인다. 이 과정에서 처음에 만든 구조를 반복해서 사용하기 때문에 파라미터를 공유하게 되는 것이다. 이 때 파라미터를 공유하지 않기 때문에 같은 구조의 블록을 12개 만드는데 BERT의 모델 사이즈 중에서 Layer가 차지하는 비중이 매우 크다. 따라서 전체 모델 사이즈가 12배 준다는 것을 예측할 수 있다.
이에 대한 성능 저하 여부 그래프도 제시했는데 L2거리와 cosine 거리 비교 시 모델의 파라미터를 공유하면서 입력과 출력의 차이가 줄어드는 지점인 평행점에 도달하면 같은 구조의 모델도 더 높은 성능을 보인다고 설명하고 있다.
3. Sentence Order Prediction(SOP)
BERT에서 NSP가 언어 모델을 학습하는 데 유용한지에 대한 의구심으로 NSP를 다른 방식으로 변형한 것이다. SOP는 두 개의 연결된 문장을 사용한다. 그리고 문장의 순서를 바꾸지 않으면 1, 바꾸면 0으로 정의하고 학습한다.
positive <CLS> 이상하게 배가 아팠다. <SEP> 그래서 병원에 갔다. <SEP>
negative <CLS> 그래서 병원에 갔다. <SEP> 이상하게 배가 아팠다. <SEP>
4. 결론
ALBERT는 BERT 모델의 성능을 비슷하거나 높은 수준으로 향상시켰고 동시에 모델 사이즈도 약 1/10 사이즈로 줄였다.
## ELECTRA(Efficiently Learning an Encoder that Classifies Token Replacements Accurately)
2020년 5월에 Google Brain과 스탠퍼드 대학교가 연구한 모델이다.
ELECTRA는 학습 효율을 개선함으로 사전 학습 시간을 현저하게 줄였다. 기존 RoBERTa, ALBERT, BERT에서는 언어 모델을 학습할 때 MLM을 사용했는데 ELECTRA는 RTD(Replaced Token Detection)이라는 방법을 사용한다.
이 모델은 GAN과 유사한 구조를 갖고 있다. 생성자는 가짜를 생성하고 구별자는 가짜를 구별하는 학습을 한다.
MLM에서 변경한 데이터를 알아내는 학습을 했는데 이 부분을 구별자가 판별해 내는 것이 RTD이다. 학습이 완료된 구별자가 electra 모델이다. 이때 생성자를 직접 사용하지 않고 생성자 역할인 MLM 모델을 사용하기 때문에 이 부분이 클 필요가 없다. 그래서 보통 이 모델에서는 MLM을 작게 만들어서 학습시킨다.
1. RTD
이 학습 효율을 개선함으로써 사번 학습 시간을 현저히 줄일 수 있었는데 원래 학습 방식에서 85%를 학습에 사용하지 않는다는 것이 매우 비효율적이라고 생각하여 각 토큰에 대해서 학습을 진행할 수 있는 방식인 RTD를 소개한다. 모든 토큰에 대해 fake/ real 여부를 판별하며 하나의 입력 데이터로 더 많은 학습을 할 수 있게 된다.
## DIstilBERT
기존의 BERT 기반 모델은 모두 기존의 CNN 또는 RNN 기반의 어어 모델보다 월등한 성능을 보인 반면 모델의 크기도 굉장히 커졌다. 이를 실제 서비스에 적용할 경우 지연 시간이 길어지게 되므로 가벼운 모델을 만들어보기 위한 경량화에 대한 연구도 활발하게 진행되고 있다.
경량화는 크게 양자화(quantization), 가지치기(pruning), 지식 증류(Knowledge Distillation) 등이 있다.
여기서는 지식 증류를 사용한 DistillBERT를 알아본다.
1. 지식 증류(Knowledge Distillation)란?
대량의 데이터셋으로 학습된 큰 모델은 많은 수의 파라미터를 갖고 있다. 그렇기 때문에 이런 모델을 실제 서비스에 적용하려면 메모리를 비효율적으로 많이 사용해야하고 모델의 실행속도도 느릴 수밖에 없다.그렇다고 모델의 크기를 줄이거나 더 작은 모델을 찾아서 학습시킨다면 모델의 정확도가 떨어지게 된다. 지식 증류는 모델의 크기를 비약적으로 줄여서 메모리 사용량과 모델의 실행속도를 크게 개선하면서 모델의 정확도는 거의 같거나 조금 낮은 정도로 유지시키는 기법이다. 즉 대량의 데이터셋으로 학습된 큰 모델이 갖고 있는 지식을 그보다 작은 모델로 이전시키는 기법이다.
지식 증류에서 이미 학습된 지식을 갖고 있는 큰 모델을 Teacher 모델이라고 하고 이 모델로부터 지식이 이전될 작은 모델을 Student 모델이라고 한다. 지식 증류로 스튜던트 모델을 학습하려면 기존에 학습된 티처모델과 학습에 사용할 Transfer 데이터셋이 필요하다.
Teacher 모델과 Transfer 데이터셋을 이용해서 지식을 증류할 때는 두 가지 목적 함수가 사용된다. 하나는 스튜던트 모델과 티처 모델간의 손실을 구하는 함수(Distillation Loss Function)이고, 다른 하나는 Student 모델과 실제 레이블 간의 손실을 구하는 함수(Student Loss Function)이다.
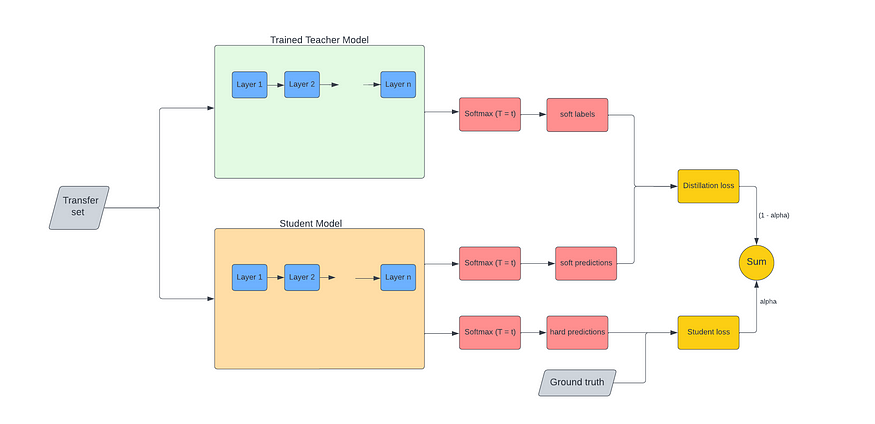
Loss 1 : Teacher - Student Cross Entropy (Distillation Loss)
\(L_ce=\sum_i t_i∗log(s_i)\)로 표현할 수 있으며, \(t_i\)는 teacher의 확률이며 \(s_i\)는 student의 확률이다.
Loss 2 : Student Masked Language Modeling Loss (MLM Loss)
일반적인 BERT의 Masked Language Modeling(MLM) loss \(L_mlm\)
Loss 3 : Teacher - Student Cosine Embedding Loss
\{ L_cos=1−cos(T(x),S(x)) \}
는 입력 벡터, 와 는 각각 teacher 모델 및 student 모델을 의미한다.
Student 모델은 티처 모델을 모방하도록 학습하게 된다. 티처 모델의 아웃풋과 스튜던트 모델의 아웃풋이 거의 차이가 없어야 한다. 이렇게 학습되도록 하려면 teacher 모델의 아웃풋과 student 모델의 아웃풋을 사용해야하는데 바로 사용하는 것이 아니라 Temperature 값으로 나눈 후 softmax를 적용한다.
저자들은 student 모델이 더욱 teacher 모델과 닮아질 수 있도록 코사인 유사도를 활용하기까지 했다. 단순히 입력 벡터 가 정답 벡터 와 같게 학습하는 지도학습 방식을 넘어, teacher 모델의 hidden 벡터와 student 모델의 hidden 벡터가 일치(align)되도록 학습하는 것이다.
soft label = softmax((티처 모델의 출력 × 1/T)
soft prediction = softmax((스튜던트 모델의 출력) × 1/T)
각 모델의 아웃풋에 softmax를 적용함으로써 값의 분포가 조금 더 부드러워지고 softmax함수를 적용하기 전에 Temperature로 나눈 후 적용하면 조금 더 부드러운 형태로 값이 분포될 수 있다.
정답값 외에 다른 레이블에 대해서의 유사도 정보를 무시하지 않게 하려고 소프트 레이블을 만든다.
*Temperate는 soft label을 위해 사용된다.
지식 증류를 학습할 때 소프트 레이블과 소프트 프리딕션 간의 손실뿐만 아니라 하드 레이블과 하드 프리딕션 간의 손실도 고려하면 훨씬 학습을 잘 시킬 수 있다.
하드 레이블은 데이터셋이 갖고 있는 원래의 레이블이고, 하드 프리딕션은 스튜던트 모델이 출력한 아웃풋이다. 하드 레이블과 하드 프리딕션 간의 손실을 지식 증류 학습할 때 고려해주면 학습 효과가 크게 증가한다.
정리하면 잘 학습된 티처 모델과 실제로 학습시킬 스튜던트 모델간의 아웃풋을 소프트하게 만들어서 손실을 계산하고 스튜던트 모델의 아웃풋과 실제 레이블 간의 손실도 게산한다. 이 두 손실값에 가중치를 적용해서 손실을 줄여나가는 방향으로 학습하면 티처모델이 갖고 있는 지식이 스튜던트 모델의 지식으로 이전되는 효과가 발생한다.
스튜던트 모델의 구조는 기본적으로 BERT와 동일하지만 토큰 타입의 임베딩과 마지막 풀링 레이어를 없애고 BERT 레이어 개수를 절반으로 줄인 형태이다. 그래서 파라미터를 줄여졌고 모델 연산 횟수 역시 감소시켰다. 연산 속도와 크기를 비약적으로 증가시켰음에도 불구하고 성능은 97% 정도 유지하고 있다고 한다.
BigBird
셀프어텐션의 시간복잡도가 O(n^2)여서 이 어텐션의 연산량을 줄이기 위한 많은 연구가 있었다.
빅버드는 긴 시퀀스를 위한 트랜스포머이다. 빅버드에서 어텐션 연산은 크게 글로벌 어텐션, 로컬 어텐션, 랜덤 어텐션으로 구성된다.
# 글로벌 어텐션
전체 문장에 대한 어텐션, 첫번째 토큰 몇 개에서 나머지 토큰들로 정보가 전이된다.
# 로컬 어텐션
가까운 단어에만 집중,
셀프 어텐션에서는 토큰 하나가 쿼리로 주어지만 그것에 대한 키가 나머지 다른 모든 토큰이 된다. 즉 하나의 토큰에 대해서 나머지 토큰과 모두 비교하는 연산을 거치게 된다. 그런데 가까이 있는 단어들에 더 많은 집중을 해야 하는 것이 일반적이다. 그렇기 때문에 로컬 어텐션은 하나의 토큰에 대한 어텐션을 계산할 때 앞뒤 몇 개의 토큰에 대해서만 어켄션을 적용한다.
# 랜덤 어텐션
임의의 토큰에 대한 어텐션, 하나의 토큰에 랜덤 토큰 몇 개를 구해서 그 토큰들과 어텐션을 계산
BERT는 하나의 토큰이 모든 토큰과 연결되어 있는 반면 빅버드는 토큰과 토큰 사이가 충분히 많이 연결되어 있되 로컬 어텐션 등을 통해서 중요한 부분에만 집중할 수 있도록 했다.
그 결과 토큰 길이에 따른 연산 시간의 증가량을 개선시켜 시간복잡도를 줄였다.
## 리포머
셀프 어텐션을 기반으로한 모델은 연산량이나 메모리 사용량 측면에서는 비효율적이다. 따라서 2020년에 구글에서 리포머 트랜스포머 라는 모델에 대한 논문을 발표했다.
# 문제점
1. N개의 레이어를 갖는 모델을 학습할 때 단일 레이어의 모델을 학습할 때보다 많은 메모리가 필요하다.
-> 활성화 함수의 값을 모두 저장해야하기 때문
2. 피드포워드 네트워크에서 사용하는 히든 레이어의 차원수는 보통 매우 크기 때문에 많은 양의 메모리를 사용한다.
-> BERT의 경우 3072~4096의 차원을 가진다. 이 네트워크가 12개 있다는 것을 의미한다.
3. 길이가 L인 시퀀스에 대해 어텐션을 수행할 때 시간/공간 복잡도가 모두 O(L^2)이다.
-> BERT에서는 모든 토큰끼리 어텐션을 계산하는데 L이 4배 길어지면 어텐션 연산에 필요한 시간과 공간의 복잡도는 16배(4^2)로 늘어난다.
# 모델 구성
리포머에서는 LSH(Locality Sensitive Hashing) 어텐션을 사용한다. 기존의 트랜스포머 구조의 경우 쿼리와 키 간의 어텐션을 게산할 때 서로의 유사도를 따지지 않고 모두 계산했으나, 리포머에서는 가까운 어텐션 끼리만 어텐션을 계산하도록 쿼리와 키간의 유사도를 측정한다. 이 때 유사도를 측정하는 방식이 LSH이다. 하나의 벡터 x에 대해 유사한 벡터 y가 있다면 x의 해시값과 y의 해시값이 같은 확률이 높다는 것이다. 비슷한 방향을 가진 벡터끼리 하나의 버킷으로 묶여 리포머 논문에서는 비슷한 버킷으로 묶는 해싱 기법으로 Angular LSH를 사용했다.
- Angular LSH는 LSH 알고리즘의 변형. 각각 고유의 코드를 가지고 미리 정의된 영역으로 분할되어 있는 구(sphere)에 점을 project한 다음, 점을 여러번 랜덤으로 회전하여 점이 속하는 bucket을 정의.
Angular LSH를 사용해 같은 버킷에 속한 벡터들끼리 어텐션을 계산하고 이 어텐션 계산을 청크(Chunk) 단위로 묶어서 수행한다. 같은 청크와 바로 전 청크끼리만 어텐션을 계산하여 GPU 상에서 연산을 분산으로 할 수 있다.
# Reversible 트랜스포머
문제점 1. N개의 레이어를 갖는 모델을 학습할 때 단일 레이어의 모델을 학습할 때보다 많은 메모리가 필요하다.
-> 역전파 연산 과정에서 미분값을 계산하기 위해 활성화 함수 결과를 저장해야 하는 문제점.
이 문제점은 Reversible 트랜스포머을 통해 해결했다. 메모리에 저장하지 않고 계산해서 쓸 수 있는 RevNet을 응용해서 Reversible 트랜스포머를 제안했다.
# RevNet
ResNet의 활성화 함수값 저장 문제를 해결하기 위해 제안된 모델인 RevNet은 특히 역전파(Backpropagation) 과정에서 메모리 효율성을 높이기 위해 설계된다. RevNet의 블록은 일반적으로 두 개의 입력 x1, x2 를 받는다.
RevNet에서 두 입력값 X1과 X2가 모두 연산을 거치긴 하지만, 그 과정과 역할이 다르다. 둘의 주요 차이점은 다음과 같다:
순서와 종속성: X1은 F(X2) 연산을 거친 결과와 더해져 Y1을 형성한다. 반면에 X2는 Y1이 이미 계산된 후에 G(Y1) 연산을 거쳐 Y2를 형성한다. 즉, X2의 연산은 Y1에 종속적이다.
연산의 복잡성: F와 G는 일반적으로 다른 연산을 수행할 수 있다. 따라서 X1과 X2가 거치는 연산의 복잡성이 다를 수 있다.
메모리 효율성: RevNet의 설계는 역전파 과정에서 Y1과 Y2만을 사용하여 원래의 입력 X1과 X2를 복구할 수 있다. 이렇게 하면 중간 계산 값을 저장할 필요가 없어 메모리 효율성이 높아진다.
정보의 흐름: X1과 X2는 서로 다른 경로를 통해 정보를 전달하고, 이는 네트워크가 다양한 특성을 학습할 수 있게 도와준다.
이러한 설계는 역전파 과정에서 중간 계산 값을 저장할 필요가 없으므로 메모리 효율성이 높아진다.
* ResNet에서는 Output=F(Input)+Input으로 이전 레이어가 전달이 되는 형식인데 레이어의 전파에 따라 값을 저장하는 것을 보여주기 위해 y1, y2로 사용하였다.

RevNet을 통해 활성화 함수를 저장하지 않고 만들어서 사용할 수 있게 됐고, 활성화 함수를 저장하는 데 필요한 메모리의 양을 없앨 수 있게 됐다. 하지만 히든 사이즈 크기가 크게는 4096까지 커질 수 있으므로 메모리의 사용량은 많다. 다행히도 선형 연산을 하기 때문에 청크 단위로 나눠서 연산해도 완전히 동일한 결과를 얻을 수 있을 수 있다. 청크 단위로 나눠서 연산을 할 경우 각 청크에서 메모리 사용량을 줄일 수 있다.
구현 소스 https://github.com/jinkilee/hello-transformer/tree/master/research
딥러닝을 이용한 자연어처리 입문 https://wikidocs.net/115055
DistillBERT 논문 리뷰 https://zerojsh00.github.io/posts/DistilBERT/
'참고 도서' 카테고리의 다른 글
| 한 권으로 끝내는 <판다스 노트> (0) | 2023.11.09 |
|---|---|
| 모두의 인공지능 기초 수학 (1) | 2023.10.13 |
| Stanford CS231n 3강 (Loss Functions and Optimization) (0) | 2023.09.13 |
| Stanford CS231N 1강, 2강(Image classifier, Linear classifier) (0) | 2023.09.12 |
| 한땀한땀 딥러닝 컴퓨터 비전 백과사전 (0) | 2023.08.04 |


