
Bamboo is coming
정규화 기법Scaling(Normalization, Standardization, regularization) 본문
Scaling
1. Normalization(min-max normalization = scaling normalization)
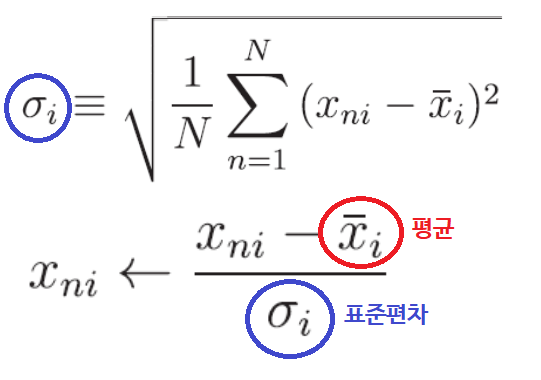
2. Standardization(z-score normalization)
정의
- 입력값의 범위(scale)를 균일하게 맞추어 같은 정도의 범위(중요도)를 가질 수 있게 해주는 것.
- 오버피팅을 막기 위한 방법 중 하나로 오버피팅의 원인이 학습 데이터와 테스트 데이터 간의 분포 차이일 수 있다.
효과
- scale이 큰 feature의 영향이 비대해지는 것을 방지.
- Local minima에 빠질 위험이 감소되고 최적값에 더 빠르게 도달할 수 있음. (학습 속도 향상)
- scale이 크면 노이즈가 생성되기 쉬워 overfitting이 될 위험이 높음.
종류
Normalization의 구분에 대해 의견이 분분하지만 Normalization을 범위를 조정하는 기법의 통칭이라고 보고 그 안에 min-max scailing, z-index normalization 등의 기법이 있다고 볼 수 있다. 하지만 이 글에서는 보편적으로 사용하는 용어 기준으로 작성했다.
1. Normalization(min-max normalization = scaling normalization)
- 모델에 투입될 모든 데이터 중에서 가장 작은 값을 0, 가장 큰 값을 1로 두고, 나머지 값들은 비율을 맞춰서 모두 0과 1 사이의 값으로 스케일링한다.
- Normalization의 목적은 데이터셋의 numerical value 범위의 차이를 왜곡하지 않고 공통 척도로 변경하는 것이다.
- 단점, 이상치(outlier)에 대해 취약함.
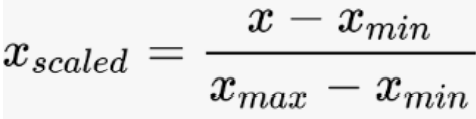
Batch normalization(배치 정규화)
배치마다 데이터의 값 분포를 일정하게 만들어 오버피팅을 억제하는 역할을 합니다. 신경망 학습을 안정화시키고, 더 빠르게 수렴하게 만들어주는 역할도 합니다. 일정한 값 분포를 유지함으로써 내부 공변량 변화(Internal Covariate Shift) 문제를 완화하고, 따라서 더 깊은 네트워크를 효과적으로 학습시킬 수 있게 해줍니다.
중요 개념
공변량(Covariate)
종속변수(dependent)에 대해 독립변수(independent)와 기타 잡음인자가 공유하는 변량을 의미한다.
즉, 여러 변수들이 공통적으로 함께 공유하고 있는 변량을 의미.
딥러닝에서는 입력 범위를 공변량이라고 지칭.
하나의 신경망에 대해 입력 범위가 바뀌는 것을 공변량 변화(Covariate shift)라고 함. (검은 고양이로 학습 -> 하얀 고양이가 입력으로 들어옴)
딥러닝 모델 내부에서 하나의 은닉층에 여러 범위의 입력이 들어오는 내부 공변량 변화(Internal covariate shift)
값 분포를 일정하게 만드는 것이 왜 더 빠르게 수렴할 수 있도록 도와주는 거야?
ChatGPT
값 분포를 일정하게 유지하면 가중치의 업데이트가 더 안정적이게 됩니다. 예를 들어, 배치 정규화 없이 신경망을 학습할 때, 앞 층의 가중치가 업데이트되면 뒷 층에 전달되는 값의 분포도 변할 수 있습니다. 이렇게 되면, 뒷 층의 가중치도 이 변화에 적응하기 위해 계속 업데이트되어야 합니다. 이러한 현상을 '내부 공변량 변화(Internal Covariate Shift)'라고 부릅니다.
내부 공변량 변화가 발생하면, 각 층은 계속해서 변하는 값 분포에 적응해야 하므로 학습이 불안정해질 수 있고, 더 많은 시간이 필요할 수 있습니다. 반면에 배치 정규화를 사용하면 이러한 문제가 완화되므로, 학습률을 높게 설정할 수 있고, 결국 더 빠르게 수렴하게 됩니다.
즉, 값의 분포를 일정하게 유지함으로써 학습 과정이 더 안정적이고 빠르게 이루어질 수 있습니다.
2. Standardization(z-score normalization)
- 어떤 글에서는 Normalization과 Regularization을 정규화, Stadandardization을 표준화라고 부르지만 z-score normalization과 Standardization이 같은 뜻으로 사용됨.
- 데이터 세트의 평균은 0이고 표준 편차는 1이 되도록 스케일링한다.
- 표준정규분포가 정규분포 중 평균이 0 표준편차가 1인 정규분포를 의미하기 때문에 표준정규분포를 따르도륙 스케일링한다고 이야기하기도 한다.
- 정규 분포의 표준화는 평균이 m이고 표준편차가 σ 인 정규 분포를 따르는 확률변수 X를 평균이 0이고 표준편차가 1인 표준정규분포를 따르는 확률변수 Z로 바꾸는 것을 의미한다.
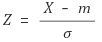
정규분포의 표준화 원리 (https://hsm-edu-math.tistory.com/597)
표준편차는 분산의 양의 제곱근인데
표준화는 평균을 0으로 이동하고 표준 편차가 1이 되도록 데이터를 조정하지만 분포의 모양은 그대로 유지됨.
예를 들어, 원본 데이터 세트가 왜곡되었거나 이중 모달(두 봉우리)인 경우 표준화 후에도 여전히 왜곡되거나 이중 모달이 된다. 데이터의 위치가 0을 중심으로 이동했지만 분포의 기본 모양은 동일하게 유지된다는 것
반면에 원래 데이터 세트가 정규 분포를 따르는 경우(평균 및 표준 편차에 관계없이) 이를 표준화하면 표준 정규 분포가 됩니다. 이는 평균과 분산이 변경된 후에도 정규 분포의 모양이 유지되기 때문입니다. 이것이 바로 표준화가 하는 일입니다.
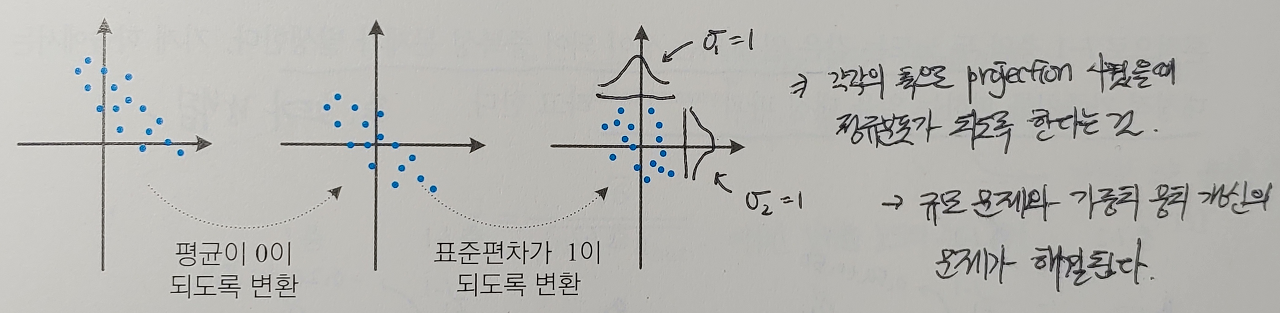
어떤 데이터가 표준 정규 분포(가우시안 분포)에 해당하도록 값을 바꿔준다고 보면 될 것 같습니다. 그래서 데이터 X가 평균값과 같다면 0으로 정규화되겠지만, 평균보다 작으면 음수, 평균보다 크면 양수로 나타납니다. 이때 계산되는 음수와 양수의 크기는 그 feature의 표준편차에 의해 결정됩니다. 그래서 만약 데이터의 표준편차가 크면, 즉 값이 넓게 퍼져있으면, 정규화되는 값이 0에 가까워집니다. 분모에 표준편차가 들어가고 분자에는 원래 데이터의 값에서 전체 데이터의 평균이 빠진다
3. Regularization
- Norm : 벡터의 크기
- L1 Norm
||x1||=n∑i=1|xi| - 가중치 행렬이 너무 커지는 것을 방지하기 위한 추가 항을 넣어 정규화를 진행시킴. 이를 프로베니우스 노름이라고 하는데 람다를 크게 해서 가중치 행렬을 0에 가깝게 만들 수 있다.
- 다양한 층을 저장하고 있긴 하지만 로지스틱 회귀와 비슷해짐

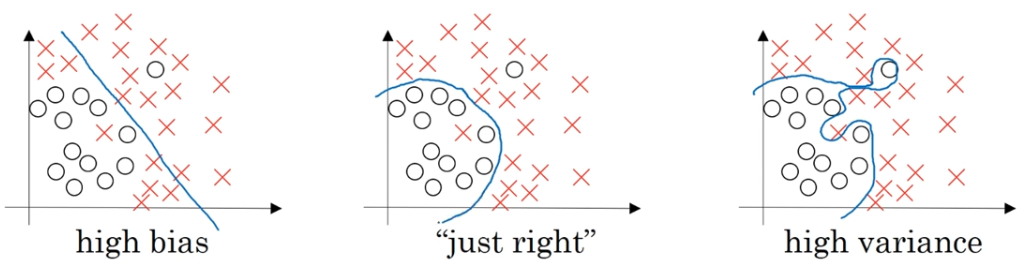
regularization의 효과는 더 간단한 네트워크를 만듬.
과대적합에 도움이 됨.
분산의 감소를 결과로 만듬
tan
https://2ndyoung.tistory.com/75
Why regularization reduces overfitting (https://www.youtube.com/watch?v=NyG-7nRpsW8)
정규화 쉽게 이해하기 (https://hleecaster.com/ml-normalization-concept/)
정규화 개념 정리 (https://blog.eunsukim.me/posts/understanding-normalization)
[딥러닝][기초]데이터 정규화 (https://hyen4110.tistory.com/20)
정규화의 목적과 방법들 (https://mole-starseeker.tistory.com/31)
Normalization vs Standardization - What’s The Difference? (https://www.simplilearn.com/normalization-vs-standardization-article)
왜, 언제 스케일링(standardization, min-max)를 수행해야 할까? (https://syj9700.tistory.com/56)
[통계] 정규화(Normalization) vs 표준화(Standardization)(https://heeya-stupidbutstudying.tistory.com/m/entry/%ED%86%B5%EA%B3%84-%EC%A0%95%EA%B7%9C%ED%99%94%EC%99%80-%ED%91%9C%EC%A4%80%ED%99%94)
정규화(normalization)와 표준화(standardization), 머신러닝 성능 향상을 위한 필수 단계 ( )https://bskyvision.com/entry/%EB%A8%B8%EC%8B%A0%EB%9F%AC%EB%8B%9D-%EB%8D%B0%EC%9D%B4%ED%84%B0-%EC%A0%84%EC%B2%98%EB%A6%AC-%EC%A0%95%EA%B7%9C%ED%99%94normalization%EC%99%80-%ED%91%9C%EC%A4%80%ED%99%94standardization
정규 분포와 정규 분포의 표준화의 의미 (https://bskyvision.com/48)
[딥러닝] 정규화? 표준화? Normalization? Standardization? Regularization?(https://realblack0.github.io/2020/03/29/normalization-standardization-regularization.html)
Regularization (https://pozalabs.github.io/Regularization/)
[DL] 딥러닝에서의 Regularization : Weight Decay, Batch Normalization, Early Stopping (https://mvje.tistory.com/m/80)
'인공지능 개념' 카테고리의 다른 글
| 데이터 세트 분리 Data set split (0) | 2023.08.04 |
|---|---|
| label smoothing (0) | 2023.08.02 |
| augmentation method(Mixup, Cutout, CutMix) (1) | 2023.07.31 |
| 모델 평가 지표(ROC, AUC, 혼동 행렬, Accuracy, Recall, precision) (0) | 2023.07.31 |
| generative ai (0) | 2023.07.25 |



