그러나 같은 이미지의 다른 해상도 쌍을 구하는 것에 어려움이 있어서 HR을 디그리데이션한 결과물을 사용함
4.1 Zero-Shot Super-resolution
zero-shot super-resolution, ZSSR - 이미지 내에 충분한 이미지 분포를 가지고 있다는 것을 고려하여 일반적인 모델이 아닌 테스트 시점에 이미지 특화 SR 네트워크로 훈련시키는 비지도 학습 네트워크를 제안했다
Nonparametric blind super-resolution을 사용한 이미지의 디그리데이션 커널을 추정하고 이 커널을 사용해서 다다른 스케일링 팩터와 증강을 가진 이미지로 디그리데이션을 수행하는 작은 데이터셋을 만든다.
그 후, 생성한 데이터셋을 이용해서 작은 SNN으로 학습을 시킨 후 최종 예측에 사용한다.
ZSSR은 cross-scale internal recurrence(해상도나 크기가 다른 상황에서 내부적으로 정보를 교환하고 다시 사용하는 기술)을 활용하여 비이상적인 조건(블러 같은 셔플된 효과, 바이큐빅 형태가 아닌 디그래데이션) 하에 1dB의 추정된 커널과 2dB의 사전 정의된 커널의 큰 품질 향상을 이뤘다.
결과적으로 이상적인 이미지(바이큐빅 형태)를 띄고 있을 경우 더 현실적인 상황에 가깝게 구현가능하다.
단점, 이미지 마다 다른 네트워크를 학습시켜야하기 때문에 추론시간이 다른 것보다 훨씬 오래 걸린다.
4.2 Weakly-Supervised Super-Resolution
화질 저하를 정의하기가 어려워서 unpaired LR-HR 이미지를 사용해서 weakly supervised 방식을 도입했다
화질 저하 패턴이 노이즈, 블러, 압축 손실 등의 다양한 원인으로 발생하고 이 원인들이 복합적으로 발생하는 경우 비선형적으로 영향을 미치기 때문에 정의하기가 어려움
Leared Degradation
그래서 화질 저하(degradation) 패턴을 학습하는 것을 목표로 한 연구 등장
화질 저하를 미리 정의하는 것은 좋은 방법이 아님 그래서 unpaired LR-HR이 그나마 괜찮은 방식
연관성이 없는 unpaired 이미지를 이용해서 HR-to-LR GAN을 학습시키고 화질 저하 패턴을 학습한다.그리고 이 GAN을 기반으로 생성된 연관성있는 paired 이미지를 사용해 LR-to-HR GAN을 다시 학습시켰다
여기서 HR-to-LR GAN에서 HR이 LR을 생성하기 위해 인풋으로 들어가기 때문에 HR의 다운스케일링된 이미지를 얻을 뿐만 아니라 LR의 진짜 분포도 얻을 수 있다.
훈련이 끝나고 난 후 생성자는 LR-HR 이미지 쌍을 생성하기 위한 화질 저하 생성 모델이 된다.
LR-to-HR GAN에서는 생성자가 HR을 예측하기 위해 생성된 LR이미지를 받는다. 이것도 역시 HR와 일치하는 결과를 얻을 뿐만 아니라 HR의 분포 또한 얻을 수 있다.
이 두 프로세스를 거쳐 이 모델은 현실 화질 저하 문제에 최신 모델들보다 더 뛰어난 성능을 보였다.
Cycle-in-Cycle Super-Resolution
비지도학습의 또 다른 접근으로 LR 공간과 HR 공간의 두 개의 도메인으로 다루는 것이다. 그리고 cycle-in-cycle 구조를 사용해서 둘 간의 매핑을 학습한다.
여기서 목적함수는 매핑된 결과가 타겟 도메인 분포와 일치하도록 강요하고 round-trip 매핑을 통해 복원가능한 이미지를 생성하는 것을 목표로 한다.
CinCGAN(2018)
4개의 Generator, 2개의 Discriminator로 구성
성과, 비지도학습인 CinCGAN이 지도학습만큼의 성능을 보였고 다양한 어려운 조건 하에서도 좋은 성능을 보였음
단점, ill-posed 문제와 복잡한 구조 때문에 학습 난이도와 불안정성을 낮춰야할 필요가 있다
4.3. Deep Image Prior
Deep Image Prior(2018)이라는 논문의 연구로 CNN이 저수준 이미지 통계 정보를 잘 파악해낸다는 것을 기반으로 무작위로 초기화된 CNN을 사용해 texture를 잡아내 이미지 복원이나 슈퍼해상도에 성능을 보였다.
가중치 초기화에 따라 오버피팅이 좌우되는만큼 초기 가중치가 중요한데 이 연구에서는 초기단계의 오버피팅이 이미지 내의 자연스러운 구조와 패턴을 복원하는 데 유용하게 사용되기 때문에 이를 활용하여 무작위 가중치로 학습을 시작한다.
초기 가중치를 달리하여 여러 CNN 구조를 만들면 LR 이미지의 모든 texture 집합을 생성하는데 clean image의 모든 집합도 생성할 수 있을거라 가정
랜덤 벡터 z를 입력으로 하는 HR 생성자 네트워크를 정의한다. 목표는 LR 이미지와 일치하는 다운샘플된 이미지를 찾는 것이 목표이다. 생성된 HR이미지가 다운샘플링 될때 입력으로 넣었던 LR이미지와 일치하는 지 확인
CNN은 랜덤으로 초기화되고 사전 훈련되어 있지 않은 것이 특징으로 CNN 구조 자체가 사전 지식이 되어 계속해서 반복하면서 LR 이미지와 일치하는 다운샘플링 이미지를 찾아나간다.
지도학습보다는 성능이 떨어질 수 있으나 전통적인 bicubic 업샘플링보다는 개선된 결과를 보인다.
5. Domain-Specific Applications
5.1 Depth Map Super-Resolution
Depth Map은 바라보는 위치에서 물체간의 거리를 기록한 것으로 자세 추정이나 segmentation에서 중요한 역할을 한다. depth map은 센서를 통해 만들어진다. 그래서 저해상도 또는 노이즈, 양자화, 값 손실 등으로 인한 화질 저하 효과들이 발생한다. 이것을 해결하기 위해 depth map에 초해상도가 도입됐다.
최근 가장 유명한 연구로는 LR depth map과 같은 이미지의 HR 이미지를 얻기 위해 또 다른 RGB 카메라를 사용한다.
연구 1, depth map의 통계 정보와 depth map과 RGB 이미지 사이의 부분적인 상관관계를 이용하여 전체적인 통계정보와 부분적인 통계 정보를 얻는다.
연구 2, 2개의 CNN을 동시에 사용하여 LR depth map을 업샘플링 시키고 HR RGB 이미지를 다운샘플링한다.그리고 RGB 특징을 LR depth map 업샘플링 가이드로 사용한다.
연구 3, 색상 정보를 더 활용하고 shape-from-shading 기법을 이용해서 SR에 가이드를 제공한다.
shape-from-shading - 이미지 내 객체의 표면 방향과 국부적인 기하학적 특성을 해석하기 위해 빛과 표면 간의 상호 작용을 분석한다. 기본적인 아이디어는 표면의 경사도와 방향이 빛의 분포와 어떻게 상호 작용하는지를 이해함으로써, 단일 이미지에서 3차원 형태를 추론할 수 있다는 것이다.
연구 4, cariational 모델 형태의 에너지 최소화 모델과 CNN을 결합하여 다른 참조 이미지 없이 HR 깊이 맵을 복구
5.2 Face Image Super-Resolution
a.k.a Face hallucination(FH)
일반적인 이미지와 달리 얼굴만의 구조적인 정보들이 많아서 얼굴 정보를 초해상도에 활용한다.
가장 간단한 방식은 생성된 이미지가 GT와 동일한 얼굴 관련 속성을 갖도록 제한하는 것이다.
연구 1, CBN(Cascaded Bi-Network)은 FH 최적화와 고밀도 상관 추정을 번갈아 하며 얼굴 사전 지식을 활용한다.
연구 2, Super-FAN, MTUN - FAN을 도입하여 end-to-end 멀티태스크 학습을 통해 얼굴 주요 정보 일관성을 유지한다.
연구 3, FSRNet은 얼굴 주요 정보 히트맵과 얼굴 파싱맵을 사용
연구 4, SICNN - 실제 신원 복구를 목표로 하여 super-identity 손실함수와 도메인 통합 훈련 방식을 채택해서 통합된 훈련을 안정적으로 수행한다.
facial prior 방식 외에도 암묵적인 방법도 연구됐다.
연구 1, TDN - 자동 공간 변환을 위해 spatial 트랜스포머 네트워크를 통합하여 얼굴 정렬 불일치 문제를 해결한다.
연구 2, TDN을 기반으로 하는 TDAE는 디코더- 인코더-디코더 프레임 워크를 사용해서 첫 번째 디코더가 업샘플링 및 노이즈 제거를 학습하고 인코더가 다시 정렬되고 노이즈가 없는 LR 얼굴로 투사하며 마지막 디코더가 투사된 HR이미지를 생성하는 방식
연구 3, LCGE - 요소 특화 CNN을 이용해 얼굴의 5가지 요소에 SR 적용하고 k-NN 검색을 HR 얼굴 요소 데이터셋에 사용하여 일치하는 패치를 찾는다. 그리고 fine-grained된 요소를 합성하고 최종적으로 이를 FH 결과에 융합시킨다.
연구 4, deblocked된 얼굴 이미지를 얼굴 요소와 배경으로 분해하고 그 component landmark를 HR 이미지를 되찾기 위해 사용한다. 배경에서는 일반적인 SR을 사용한 후 완전한 HR 얼굴에 융합시킨다.
다른 관점으로부터의 FH도 발전시킨다.
연구 1, Attention-FH - 사람의 주의 이동 방식에 영감을 받은 이 연구는 주의가 집중된 패치를 순차적으로 발견하고 지역적인 향상을 수행하기 위해 반복 정책 네트워크에 의존한다. 그 결과적으로 얼굴 전역 상호 의존성을 완전히 활용한다.
연구 2, UR-DGN - 적대적 학습을 동반한 SRGAN과 비슷한 네트워크를 채택한다.
연구 3, 일반 생성기와 클래스별 판별자로 구성된 다중클래스 GAN 기반 FH 모델
연구 4, 기존 GAN을 기반으로 얼굴 속성 정보를 추가로 활용해 지정된 속성을 가진 FH 수행
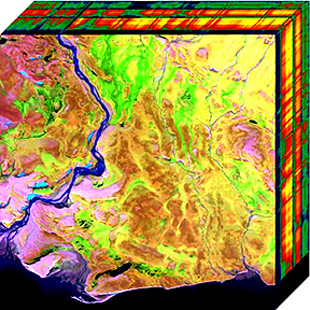
5.3 Hyperspectral Image Super-Resolution
Two-dimensional projection of a hyperspectral cube
팬크로마틱 이미지(PAN)에 비해 수백 개의 대역을 포함하는 초분광이미지(HSI)는 풍부한 스펙트럭 특징을 제공하며 다양한 비전 작업에 도움이 된다. 그러나 하드웨어의 한계로 인해 고품질 HSI를 수집하는 것은 매우 어렵다
그래서 SR이 이 분야에도 도입되어 HR PAN 이미지와 LR HSI 이미지를 결합하여 HR HSI을 추측하는 것을 목표로 하는 경향이 있다.
연구 1, SRCNN을 적용하고 몇개의 비선형 방사능 인덱스를 성능향상을 위해 통합했다.
연구 2, 2개의 인코더-디코더 네트워크를 학습시켜 PAN과 HSI 위에서 SR을 형성하고 디코더를 공유하고 각도 유사성 손실 및 재구성 손실과 같은 제약 조건을 적용하여 SR 지식을 PAN->HSI로 전송한다
연구 3, HSI SR에 대한 카메라 스펙트럼 응답(CSR, Camera Spectral Response) 기능의 효과를 평가하고 최적의 CSR을 자동적으로 선택하거나 설계할 수 있으며 최신 기술을 능가하는 CSR 제안
5.4 Real-World Image Super-Resolution
일반적으로 SR 모델 훈련을 위한 LR 이미지들은 바이큐빅 다운샘플링등을 이용해 수동으로 다운샘플링을 시킨다.
그러나 현실 세계의 카메라는 12bit 또는 14bit의 RAW 이미지를 캡쳐하고 카메라 내의 이미지 신호 프로세서(ISP)를 통해 디모자이킹, 디노이징, 압축 등을 수행한 후 최종적으로 8bit 이미지를 생성한다.
이 작업을 통해서 RGB 이미지는 원래의 신호들을 많이 잃게 되고 카메라로부터 찍힌 이미지와 매우 다른 이미지가 된다. 그래서 수동으로 다운샘플된 이미지를 SR에 사용하는 것은 부적절하다.
이 문제를 해결하기 위해서 연구자들은 real-world 이미지를 어떻게 사용해야할지 연구했다.
연구 1, 이미지 해상도(R)과 field-of-view(V)의 관계를 분석하여 real-world dataset City100을 수행하는 데이터 취득 전략을 제안했다.
연구 2, 카메라의 광학 줌을 통해 real-world dataset SR-RAW (HR RAW-LR RGB 짝)을 만들고 오정렬 문제를 해결하기 위해 contextual 대칭 손실을 제안했다.
연구 3, 이미징 과정을 시뮬레이션하여 사실적인 훈련 데이터를 생성하기 위한 파이프라인을 제안하고 RAW 이미지에서 원래 캡처된 방사 정보를 활용하기 위해 이중 CNN을 개발한다. 또한 효과적인 색상 보정 및 다른 센서로의 일반화를 위해 공간적으로 다양한 색상 변환 학습을 제안
5.5 Video Super-Resolution
다수의 프레임이 더 많은 신 정보를 제공한다. 신 정보에는 intra-frame 공간 독립성뿐만 아니라 inter-frame의 시간적 독립성이 있다.(움직임, 밝기, 색상 전환 등)
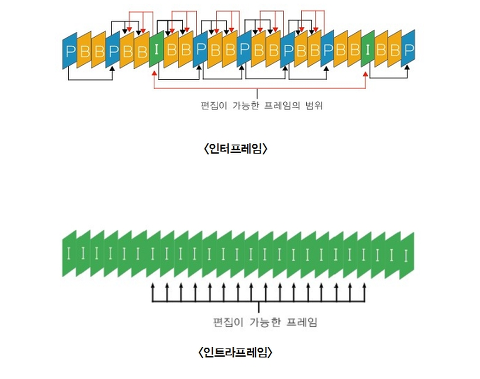
인트라 프레임 - 영상이 독립적으로 DCT 부호화되고 재생, 편집 시 프레임 단위로 편집과 재생이 가능하다. 모든 프레임의 정보를 해당 프레임에서 다 가지고 있다. 그림 파일의 jpg와 비슷해서 화질이 좋고 검색이 빠르고 편집이 용의하나 용량이 큰 단점이 있다.
인터 프레임 - 프레임 이상의 정보를 압축하고 있으며 I를 제외한 B, P 프레임을 말한다. 특정 프레임에 영상 주요 정보를 모두 가지고 있고 다른 프레임은 이 특정 프레임의 정보를 기준으로 만들어진다. 장점으로는 용량 대 화질이 우수한 영상을 만들 수 있다는 것이고 단점은 각 프레임 영상에 대한 모든 정보를 다 가지고 있는 것이 아니라 편집속도가 느리고 편집이 용이하지 않다.
그래서 최근 연구는 시공간( spatio-temporal ) 독립성의 사용과 동작 보정, 반복 방식 등을 더 낫게 하는 것에 중점을 둔 연구를 하고 있다.
Optical flow-based methods
a.k.a motion field - 움직임이 발생한 모든 점의 모션 벡터로 얻어낸 2차원의 모션맵
연구 1, Optical flow-based method를 이용해 HR 후보를 생성하고 이를 CNN으로 앙상블
연구 2, VSRnet, CVSRnet - Druleas 알고리즘으로 움직임 보상을 처리하고 CNN을 사용해 연속된 프레임을 입력으로 받아 HR 프레임을 예측
연구 3, 수정된 Optical flow-based 정렬을 수행하고 다양한 시간 척도로 HR 프레임을 생성하고 이를 적응적으로 합산하는 시간 적응형 네트워크 제안
Motion Compensation
연구 1, VESPCN 인접 프레임을 기반으로한 동작 보정을 학습하기 위해 훈련가능한 공간 트랜스포머를 활용한다. 그리고 여러개의 프레임이 spatio-temporal ESPCN에 end-to-end 예측을 위해 들어간다.
연구 2, 정확한 LR 이미징 모델에서 root를 추출하고 서브픽셀과 유사한 모듈을 제안하여 움직임 보정과 초고해상도를 동시에 달성함으로써 정렬된 프레임을 보다 효과적으로 융합
recurrent methods
명확한 동작 보정 없이 시공간 독립성을 포착하는 것이 새로운 트렌드
연구 1, DRCN - 양방향 프레임워크를 사용하고 CNN, RNN 그리고 조건부 CNN을 시간적, 공간적, 시공간적 독립성을 모델링 하는데에 사용한다.
연구 2, STCN - deep CNN과 양방향 LSTM을 사용하여 공간적, 시간적 정보를 추출해 낸다.
연구 3, FRVSR - 기존에 추론된 HR 추정치를 사용하여 두 개의 deep CNN이 반복적인 방식으로 후속 HR 프레임을 재구성한다.
연구 4, FSTRN - 훨씬 작은 두 개의 3D 컨볼루션 필터를 사용하여 원래의 큰 필터를 대체하므로 낮은 게산 비용을 유지하면서 더 심층적인 CNNdmf xhdgo tjdsmddmf gidtkdtlzlsek.
연구 5, RBPN - 반복 인코더-디코더를 통해 공간 및 시간적 컨텍스트를 추출하고 이를 역투영 메커니즘에 기반한 반복적인 정제 프레임 워크와 결합한다.
연구 6, FAST - 압축 알고리즘에 의해 추출된 구조와 픽셀 상관관게에 대한 간결한 설명을 활용, 한 프레임에서 인접 프레임으로 SR 결과를 전송하며 성능 손실이 거의 없이 최첨단 Sr 알고리즘을 훨씬 가속화한다.
연구 7, 각 픽셀의 로컬 시공간적 이웃을 기반으로 동적 업샘플링 필터와 HR 잔여 이미지를 생성하고 명시적인 움직임 보정을 피한다.
5.6 Other Applications
연구 1, Perceptual GAN - 작은 물체가 큰 물체와 비슷한 특성을 가지고 발견을 더 잘 할 수 있도록 하는 초해상도 표현을 통해 작은 물체를 탐지하는 문제를 다룬다.
연구 2, FSR-GAN - 픽셀 공간이 아니라 feature 공간에서 작은 이미지의 초해사도 수행, 그리고 raw poor features가 높은 discriminative으로 변형된다
discriminative - 저해상도 입력에서 고해상도 이미지를 재구성할 때, 중요한 세부 정보와 패턴을 정확히 식별하고 복원하는 능력을 강조하는 방법
연구 3, parallax prior를 스테레오 이미지의 sub-pixel 정확도로 HR 복원을 위해 사용했다.
parallax는 시차라는 뜻으로 천문학에서 사용하는 용어이다. 즉 멀리 있는 물체는 천천히 움직이고, 가까이 있는 물체는 빨리 움직이는 현상을 의미. 이 현상을 이용하면 입체감, 실체감을 높여서 보다 인상적인 디자인을 할 수 있습니다.
연구 4, parallax-attention -
연구 5, 3D 기하학 정보와 초해상도 3D object texture 맵을 결합한 연구
연구 6, view 이미지를 한 가지 광원에서 여러 그룹으로 나누고 매 그룹마다 매핑 학습, 그리고 고해상도 광원을 재구성한 모든 그룹의 잔차를 결합
나의 첫 서베이 논문 읽기를 마쳤다. 연구들의 흐름을 볼 수 있어서 뜻깊은 시간이었고 연구는,, 어쩌면 잘 조합하는 것만으로도 훌륭한 연구가 되는 것 같다. 앞으로도 열심히 논문 읽고 공부해보겠습니닷