
Bamboo is coming
Deep Learning for Image Super-Resolution: A Survey(2) (2021.10) 본문
Deep Learning for Image Super-Resolution: A Survey (2021.10) IEEE, 1400회 인용, 23p
🎈목차
- 기존 연구
- class methods
- deep-learning based methods
- SR 문제 정의
- 유명 데이터셋
- 성능 평가 지표, IQA
- PSNR, SSIM, MOS, Learning-based Perceptual Quality, Task-Based Evaluation ..etc
- Challenges
- NITRE, PRIM
- Supervised Super-Resolution
- SR Framework
- Pre-upsampling SR, Post-upsampling SR, progressive upsampling SR, Iterative up-and-down sampling SR
- Upsampling Methods
- Interpolation-Based Upsampling, Learning-Based Upsampling
- ----------------------------------(1)------------------------------
- network design
- Residual Learning
- Global Residual Learning, Local Residual Learning
- Recursive Learning
- Multi-Path Learning
- global multi-path learning, local multi-path learning, scale-specific multi-path learning
- Dense Connection
- Attention Mechanism
- Channel Attention, Non-Local Attention
- Advanced Convolution
- Dilated Convolution, Group Convolution, Depthwise Separable Convolution
- Region-Recursive Learning
- Pyramid Pooling
- Wavelet Transformation
- Desubpixel
- xUnit
- Residual Learning
- Learning Strategies
- Loss Functions
- Batch Normalization
- Curriculum Learning
- Multi-Supervision
- Other Improvements
- Context-Wise Network Fusion(CNF)
- Data Augmentation
- Multi-Task Learning
- Network Interpolation
- Self-Ensemble
- State-of-the-Art Super-Resolution Models
- ----------------------(2)-------------------------
- SR Framework
- Unsupervised Super-Resolution
3.3 network design
네트워크 디자인도 중요한 요소가 되었는데 네트워크 설계의 필수 원칙 또는 전략으로 분해하여 소개하고 장점과 한계를 설명한다.
3.3.1 Residual Learning
- Global Residual Learning
- SR은 input과 target이 매우 밀접하게 연관되어 있어 이들의 차이인 residual을 학습하려고 시도함.
- 전체 이미지에서 다른 이미지로의 변환을 학습하는 대신 잔차맵을 학습하여 고주파 디테일을 복원
- 대부분의 영역에서 잔차가 거의 0에 가까워 모델 복잡성과 학습난이도 감소.
- 고주파 detail은 이미지에서 뾰족한 에지, 선명한 세부 사항 또는 작은 텍스처와 같은 고해상도 이미지의 세부적인 특성을 나타내기 때문에 고주파 디테일을 복원함으로써 해상도 향상.
- input과 target을 직접 연결하여 레이어 간의 잔차를 학습하여 네트워크가 더 복잡한 함수를 근사화하도록 도움
- Local Residual Learning
- ResNet에서의 잔차학습과 유사함
- 네트워크 깊이 증가에 따라 발생하는 성능 저하 문제를 완화하고 학습 난이도를 줄이며 학습능력을 향상시키기 위해 사용된다.
- 네트워크 내부에 단축 경로를 추가하는 등 모델의 특정 부분에서만 잔차를 학습하므로 모델의 일부를 더 세밀하게 조정하는 데 도움이 됩니다.

3.3.2 Recursive Learning
- 엄청난 양의 파라미터를 도입하는 대신 재귀하는 구조를 만드는 것으로 SR을 수행하는 방식
- DRCN - single conv layer를 쌓아 재귀 학습하여 41x41 수용영역을 만듬
- DRRN, CARN - ResBlocks으로 재귀 학습한 네트워크
- Feedback network - up-and-down sampling SR framwork를 사용하여 재귀학습 기반으로 전체 네트워크의 가중치가 모든 재귀 동작들에 공유되는 구조를 만듬
- 그 외에도 upsampling module을 재귀 구조로 차용하여 모델 사이즈와 performance loss를 줄이거나 LR-HR간의 신호를 교환하기 위해 dual-state 재귀 네트워크를 사용하는 등의 시도가 있었음
- 재귀학습은 더 적은 파라미터로 향상된 표현을 학습할 수 있지만 여전히 높은 계산 비용을 피할 수 없다. 그리고 계속해서 소실되거나 넘치는 기울기 문제를 가져온다.
- 이러한 문제를 해결하기 위해 residual learning이나 multi-supervision은 재귀학습과 결합하여 사용된다.

3.3.3 Multi-Path Learning
- multi-path 학습은 다양한 경로를 통해 전달하고 각 경로에서 다른 연산을 수행한 후 다시 융합하는 방식
- global multi-path learning
- 다양한 측면의 이미지 특징을 추출하기 위해 여러 경로를 사용, 이는 propagation 과정에서 서로 교차되며 학습능력을 크게 향상 시킬 수 있다.
- LapSRN(Laplacian Pyramid Super-Resolution) - coarse-to-fine 단계로 sub-band 잔차를 예측하는 특징 추출 경로와 두 경로의 신호를 기반으로 HR 이미지를 구성하는 또다른 경로를 포함한다.
- DSRN - 저차원, 고차원 공간에서 정보를 추출하는 경로와 각각 정보를 교환하여 학습 능력을 향상시킨다.
- Pixel resursive SR은 이미지의 global 구조를 캡쳐하는 조건 경로와 생성된 픽셀의 serial dependence을 포착하는 우선 경로를 사용한다.
- serial dependence: 시간 순서에 따라 발생하는 데이터 포인트 간의 상관 관계
- local multi-path learning
- 3x3과 5x5 사이즈의 커널을 가진 conv 레이어를 사용해 동시에 특징을 추출한 다음 출력들을 연결하고 같은 연산을 다시 수행, 그리고 1x1 합성곱을 추가적으로 적용한다
- multiple scale로부터 이미지 특징을 더 잘 추출할 수 있고 성능을 더욱 향상 시킬 수 있다.

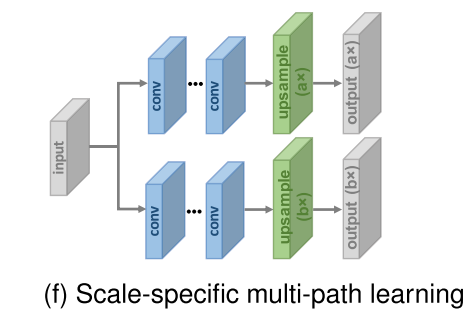
- scale-specific multi-path learning
- single network에 multi-scale SR을 대처하기 위해 이 학습 방법을 제안했다.
- 주요 요소(특징 추출을 위한 중간 레이어)를 공유하고 scale-specific 전처리 과정과 업샘플링 과정을 네트워크 앞과 뒤에 각각 붙인다.
- 훈련 중에는 선택한 스케일에 해당하는 경로만 활성화되고 업데이트된다. MDSR은 서로 다른 스케일에 대해 대부분의 파라미터를 공유해서 모델 크기를 줄이고 단일 스케일 모델과 비슷한 성능을 보여준다.

3.3.4 Dense Connection
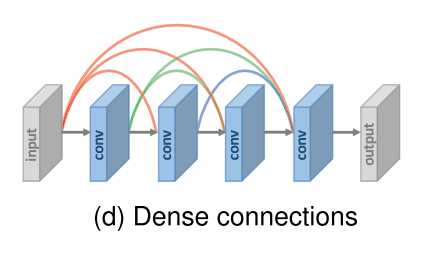
- Dense block의 각 레이어들을 위해, 모든 선행 레이어의 특징맵은 인풋으로 사용되고 그 특징맵들은 후속 레이어들의 인풋으로 또 사용된다.
- 이러한 학습방식으로 연결 갯수는 l(l-1)/2개가 된다.
- 이 덴스 커넥션은 기울기 소실을 완화시키고 신호 전파 향상, 특징 재사용에 도움이 될 뿐만 아니라 작은 성장률(덴스 블럭 채널의 수)과 인풋 특징 맵을 모두 결합한 후 채널을 squeezing하는 것으로 모델 사이즈를 상당히 줄인다.
- low-level 과 high-level feature의 융합하여 고퀄리티의 세부사항을 재구성하는데 필요한 풍부한 정보를 제공하기 위해서 dense 연결이 도입되었다.
3.3.5 Attention Mechanism
- Channel Attention
- 다른 채널 사이의 특징 표현의 상호의존성과 상호작용을 고려하여 "squeeze-and-excitation"을 제안했다
- input channel은 GAP(Global Average Pooling)을 이용해 상수값을 가지는 채널 discriptor로 squeeze되고 이 discriptor는 두 개의 dense layer에 입력 레이어를 위한 채널별 scaling factor를 생성하기 위해 제공된다.
- 최근 SR을 이용한 채널 어텐션 메커니즘을 통합하고 RGAN을 제시했다.
- 특징간의 상관관계를 배우기 위해 second-order channel attention(SOCA) 모듈을 제시하기도 했다. SOCA는 GAP 대신에 2차 특징 통계를 사용하여 적응적으로 재조정하고 더 많은 정보와 변별력있는 표현을 추출할 수 있게 해준다.

- Non-Local Attention
- 현존하는 SR 모델은 매우 한정적인 local 수용 영역을 가지고 있다. 하지만 먼 거리에 있는 영역이나 질감이 local patch 생성에서 매우 중요하게 작용한다.
- 그래서 local and non-local 어텐션 블럭이 픽셀 사이의 큰 영역의 독립성을 잡아내는 특징 추출을 제안했다.
- 구체적으로 특징 추출을 위한 trunk branch와 trunk branch의 특징을 적응적으로 재조정하기 위한 (non)local mask brach를 제안했다.
- local branch는 인코더-디코더 구조를 사용해서 local attention을 학습하고
- non-local branch는 내장된 가우스 함수를 사용해서 특징맵의 모든 두 위치 인덱스 간의 쌍 관계를 평가하여 스케일링 가중치를 예측한다.
- 이러한 메커니즘을 통한 공간적 attention을 더 잘 포착하고 표현 능력을 더욱 향상시킨다.
- 이 non-local 방식은 장거리 공간 컨텍스트 정보를 포착하는 데에 더 유용하다.
3.3.6 Advanced Convolution
conv 연산이 딥러닝의 주된 연산이 되어 연구자들은 이를 더 발전시키고자 함
- Dilated Convolution
- contexture information이 SR 사실적인 디테일을 생성해 내는 것은 잘 알려진 사실이다.
- 따라서 기본 conv연산을 확장된 conv연산으로 교체하고 수용영역을 2배 이상 증가시키고 더 나은 성능을 달성했다.
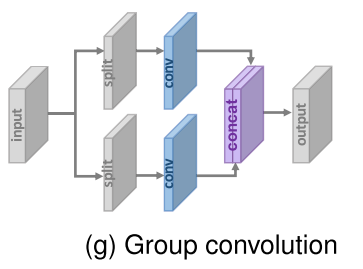
- Group Convolution
- IDN, CARN-M
- 기본 연산을 그룹 conv 연산으로 교체
- 그룹 conv 연산으로 약간의 성능 손실을 감수하면서 파라미터와 연산 개수를 크게 줄임
-
- Depthwise Separable Convolution
- factorized depthwise conv와 point wise conv로 구성되어 있으며 factorized depthwise conv 에서 입력 차원 별로 연산을 수행하고 point wise에서 채널별 특징맵을 결합하고 새로운 특징맵을 생성한다.
- 정확도는 감소하더라도 기존의 연산보다 가볍고 효율적이다.
3.3.7 Region-Recursive Learning
- 픽셀 독립적인 작업으로 취급하는 기존 모델의 문제점
- Pixel recursive super resolution에서 global contextual 정보를 포착하고 직렬 생성 의존성을 각각 캡쳐하는 두 네트쿼크를 사용하여 픽셀별로 생성을 수행하는 픽셀 재귀학습을 제안했다.
- 이 방법으로 매우 낮은 해상도의 얼굴 이미지에 실제같은 머리카락과 피부 디테일을 합성하며 MOS 테스팅에서 이전 방법을 능가한다.
- Attention-FH(Attention-Aware Face Hallucination)
- 인간의 눈은 한 순간에 한 곳에 집중되며, 중요한 정보나 객체에 주의를 이동시켜 가면서 환경을 인식한다. 이러한 메커니즘은 정보 처리의 효율성을 높이고, 복잡한 시각적 환경에서 필요한 정보를 더 잘 추출할 수 있게 한다.
- 사람의 주의 이동 메커니즘에 영향을 받아 순차적으로 주목하는 패치를 발견하고 국소부위 향상을 수행하기 위해 반복적인 정책 네트워크에 의존하는 전략을 채택한다.
- 특정 영역에서는 좋은 성능을 보이는 것처럼 보이지만
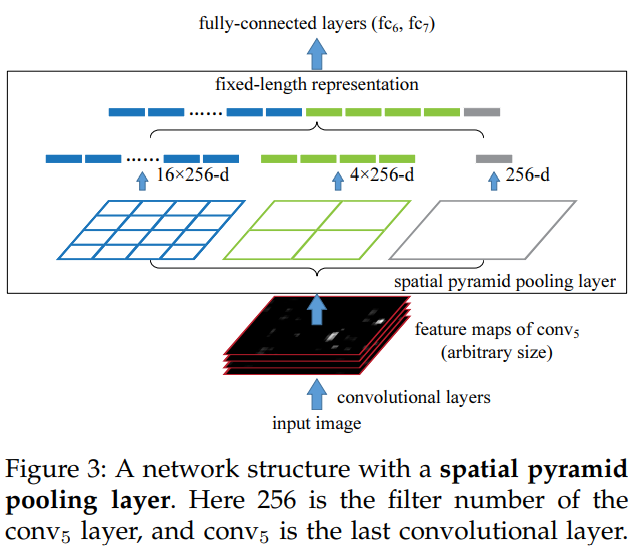
3.3.8 Pyramid Pooling
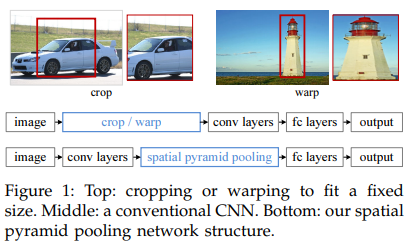
- SPP(Spatial Pyramid Pooling)을 본따 만들었다.
- CNN에서 학습 일관성 등의 이유로 FC 레이어를 고정시키는데 이 때문에 인풋 이미지 사이즈를 조정하는 것이 기존 관례였다.
- 이미지를 자르거나 왜곡시키면 conv 필터의 슬라이딩 윈도우 특성상 성능이 떨어질 수도 있다.
- 그래서 제안한 것이 이 pooling으로 16, 4, 1의 사이즈로 각각 풀링을 하고 이를 concat하여 flatten하는 방식이다.
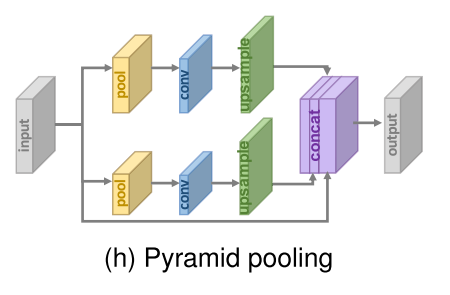
- “Pyramid scene parsing network,” (2017)에서 제안한 네트워크에서는 이미지를 M*M 사이즈로 나눠 GAP을 거친 후 M*M*C 사이즈로 줄인다. 이를 1*1 conv 연산 시켜 단일 채널로 압축하고 저차원 특징맵은 원래 사이즈에 맞춰 이중선형 보간법으로 업샘플링한다.
- M을 조정함으로써 목적에 따라 전역적, 지역적 문맥 정보를 효과적으로 통합할 수 있다.
3.3.9 Wavelet Transformation
- Wavelet은 평균이 0이고 빠르게 크기가 줄어드는 진동파동이다. 유한기간동안 존재하며 다양한 모양이 존재한다.
- 데이터, 신호는 천천히 변화하는 경우가 많고 이미지는 명암에 따라 급격히 변화하는 경우가 많은데 푸리에 변환은 데이터 변화에는 효율적이나 갑작스러운 변화에는 맞지 않는다. 시간과 공간에 국한되지 않고 영원히 진동하는 사인파 특성 때문이다.
- 압축된 wavelet은 엣지등을 잡아낼 수 있는 고주파를 표현하고 늘여진 wavelet은 면 등의 저주파를 표현한다.
- 따라서 wavelet transformation은 이미지에 효과적인 표현 방식이다
- 2017년 최초로 WT와 딥러닝을 결합한 SR 모델이 나왔고 인풋으로 삽입된 LR의 sub-band를 얻고 HR sub-band에 대응하는 잔차를 예측한다.
- WT와 역WT는 LR 인풋을 분해하고 HR 아웃풋을 재구성한다.
- DWSR, Wavelet-SRNet - wavelet 도메인에서 더 복잡한 구조의 SR을 구현
- MWCNN - multi-level WT와 sub-band를 인풋으로 넣은 CNN을 결합하여 둘 간의 연관성을 더 잘 찾아냈다. (기존은 sub-band가 독립적이었으나 이를 연관시켜서 구성)
- WT를 활용한 모델은 모델사이즈를 줄이고 계산비용을 줄이며 경쟁력 있는 성능을 유지한다.
3.3.10 Desubpixel
- 추론 속도를 향상시키기 위해 등장.
- 시간이 많이 걸리는 특징 추출은 저차원에서, 서브픽셀 layer의 역 셔플 연산인 desubpixel을 제안
- desubpixel은 이미지를 나누고 다른 채널에서 쌓아서 정보 손식을 막는다.
- 이 방법으로 모델의 앞 부분에서 desubpixel로 인풋이미지를 다운샘플링하고 저차원에서 표현을 학습한다. 그리고 타겟 사이즈로 마지막에 다시 업샘플링을 한다
- 이 방식은 스마트폰 PIRM 챌린지에서 빠른 속도로 가장 높은 점수를 얻었다.
-

이전 게시물에서 언급한 sub-pixel의 반대 버전
3.3.11 xUnit
- 공간적인 특징 처리과정과 비선형 활성화 함수를 합치고 복잡한 표현을 더 잘 학습시키기 위해서 공간 활성화 함수를 학습을 위한 xUnit이 발표됐다.
- ReLU가 입력에 대한 요소별 곱셈을 수행하기 위해 가중치맵을 결정하는 것으로 간주되는 반면 XUnit은 컨볼루션과 가우시안 게이팅을 통해 가중치 맵을 직접 학습한다.
- xUnit은 더 많은 계산 비용이 들지만 성능에 미치는 효과로 인해 모델 크기를 크게 줄이면서도 ReLU와 성능을 맞출 수 있다. 이러한 방식으로 저자들은 모델 크기를 50%까지 줄였다.
3.4 Learning Strategies
3.4.1 Loss Functions
SR에서 손실함수는 재구성 에러를 측정하고 모델 최적화를 유도하는 역할을 한다. 기존에는 pixel-wise L2 loss를 사용했으나 최근에는 재구성 성능을 정확하게 측정할 수 없다는 게 밝혀졌다. content loss, adversarial loss 등의 다양한 손실함수로 재구성 에러를 측정하고 더 사실적이고 고퀄리티의 결과를 만들어내고 있다.
- Pixel Loss
- L1, L2 Loss, Charbonnier loss
- L2 Loss는 L1 에 비하명 큰 에러에 페널티가 심하고 작은 에러에 관대하다 그래서 결과가 너무 매끄러울 수 있다.
- 실제로 L1 loss가 더 나은 성능과 수렴을 보인다.
- PSNR은 pixel-wise 차이와 관련이 있고 픽셀 손실을 최소화하는 것이 곧 PSNR을 극대화하기 때문에 pixel loss는 점차 가장 널리 사용되게 됨
- pixel loss는 이미지 품질(perceptual quality, texture 등)을 고려하지 않기 때문에 고주파 디테일이 부족하고 지나치게 부드러운 텍스쳐로 인해 불만족되는 경우가 있다.
- Content Loss
- content loss는 사전학습된 이미지 분류 네트워크를 사용해서 이미지 간의 의미적 차이를 평가한다. 이는 두 이미지의 high-level 표현 사이의 유클리드 거리로 표현된다.
- 분류 네트워크의 계층적 이미지 특징의 학습된 지식을 SR 네트워크로 변환한다.
- pixel의 일치도를 비교했던 pixel loss와 다르게 의미적으로 일치하는 지를 확인한다. 그래서 시각적으로 더욱 나나은 결과를 내고 널리 사용된다.
- 여기서 가장 널리 사용되는 사전학습 네트워크는 VGG, ResNet이다
- Textual Loss
- 동일한 스타일(색상, 질감, 대비)를 비교하는 것으로 서로 다른 특징 채널간의 상관관계로 간주되며 그람 행렬로 정의된다
- textual loss의 도입으로 더욱 사실적인 질감을 만들어내고 더욱 만족스러운 결과를 만들어냈다.
- 그럼에도 불구하고 텍스쳐에 맞게 패치크기를 결정하는 것은 여전히 실험에 맡겨져 있다. 너무 작으면 아티팩트가 발생하고 너무 크면 다른 텍스쳐 영역에 평균화되기 때문에 이미지 전체에 아티팩트가 발생한다.
- Adversarial Loss
- generator와 discriminator로 구성된 GAN
- discriminator - 생성된 결과와 target distribution에서 샘플링된 인스턴스(이미지)를 입력으로 받아 각 입력이 target distribution에서 나왔는지 여부를 판별
- 학습과정
- (a) generator를 고쳐 discriminator가 더 잘 판별할 수 있도록 학습
- (b) discriminator를 고쳐 generator가 discriminator를 속일 수 있도록 학습
- SR에서는 SR model을 생성자로 사용하고 판별자를 생성된건지 아닌지 판별하는 용으로 사용한다.
- SRGAN, 크로스 엔트로피를 기반으로 adversarial loss를 사용하는 SRGAN이 처음으로 제안됐다.
- SRFeat, adversarial loss에 초점을 맞춘 것과 달리 pixel 수준의 판별자가 무의미한 고주파 노이즈를 발생시킨다고 주장하며 또다른 특징 수준의 판별자를 추가하여 사전 학습된 CNN이 추출한 고수준 표현에서 작동하여 속성 포착
- MOS 테스트에 따르면 Adverarial Loss와 Content Loss로 훈련된 SR 모델이 Pixel Loss로 훈련된 모델에 비해 PSNR은 낮지만 지각품질은 크게 향상된다.
- 판별기는 실제 이미지에서 학습하기 어려운 잠재 패턴을 추출하고 보더 사실적인 이미지를 생성하는 데 도움으 주지만 GAN 학습 과정이 여전히 어렵고 불안정하다.
- Cycle Consistency Loss
- CycleGAN에서 도입된 개념
- G : X → Y 를 학습, F : Y → X 와 같은 역방향 매핑을 함께 진행, F(G(x)) 가 X와 유사해지도록 강제하는 cycle consistency loss 도입

- upsampling LR -> HR, downsampling HR-> LR
- 픽셀 수준의 일관성을 제한하기 위해 사이클 일관성 손실이 도입.
- CycleGAN에서 도입된 개념
- Total Variation Loss
- 생성된 이미지의 노이즈를 억제하기 위해서 도입된 TV loss
- 이웃 픽셀과 이미지 내 노이즈 값의 차의 절댓값을 합한 것으로 정의된다.
- Prior-Based Loss
- 외부 사전 지식으로 생성을 제한하기도 함.
- Face Alignment Network(FAN), 얼굴 주요 요소를 유지하기 위해 도입됨
- FAN은 얼굴 정렬 정보를 제공하기 위해 사전 학습 및 통합된 다음 SR과 공동으로 학습된다.
- 사실, content loss와 Texture Loss는 분류 네트워크에 도입된다. 본질적으로 손실함수가 SR 이미지에 대한 사전 정보를 제공한다.
3.4.2 Batch Normalization
Covariate shift(공변량 변화)를 제거하기 위해 BN이 제안됐다. 각각의 mini-batch에 normalization을 수행하고 표현 능력을 보존하기 위해 각각 채널의 두 변환 매개변수를 학습한다. BN이 중간 피처 분포를 교정하고 기울기 소실을 완화하면서 더 높은 학습률과 초기화에 덜 신경써도 되게 되었다. 그래서 BN이 SR model에 널리 쓰이게 됐다.
그러나 BN이 이미지의 크기 정보를 잃고 네트워크 범위 유연성을 제거한다고 주장했다(Enhanced deep residual network, 2017). 따라서 BN을 제거하고 절약된 메모리 비용을 훨씬 더 큰 모델을 개발하는 데 사용하여 성능을 크게 향상시켰다.
3.4.3 Curriculum Learning
- Curriculum Learning은 쉬운 작업에서부터 점점 난이도를 올려가는 것을 의미한다. SR이 ill-posed problem이고 큰 스케일링 팩터, 노이즈, 블러링 등의 문제를 겪고 있기 때문에 커리큘럼 러닝은 학습 난이도 감소의 일부분이 되었다.
- ProSR, ADRSR, Progressive CARN은 큰 스케일링 팩터를 가진 SR의 난이도를 줄이기 위해 제안되었으며, 각각의 구조와 학습 방법이 발전되었다.
- ProSR은 이전 레벨의 결과와 현재 레벨의 결과를 선형적으로 혼합. 이는 두 결과를 일정 비율로 결합하여 최종 이미지를 생성하는 방식이다.
- ADRSR은 두 결과물을 결합한 후, 이를 다른 컨볼루션 레이어를 통과시켜 처리한다
- progressive CARN은 기존의 복원 블록을 사용하여 2배 해상도로 업샘플링한 이미지를 생성하고, 이를 이전 단계의 이미지와 교체한다. 이는 점진적으로 해상도를 향상시키는 방식을 취한다.
- 8X SR 문제를 3개의 sub-problems(1X to 2X, 2X to 4X, 4X to 8X)로 나눠서 각각 문제에 대해 독립적인 네트워크를 훈련시키고, 그리고 2개의 네트워크를 합치고 fine-tuned 시킨다. 그리고 3번째 네트워크도 똑같이 수행한다. 4X SR 네트워크를 다시 1X to 2X, 2X to 4X로 나누고 디노이징 또는 디블러링의 서브 문제로 각각 또 나눈다.
- SRFBN이 악조건에서도 효과적으로 작동하기 위해 해당 전략을 채택한다.
- 흔한 학습 단계와 비교했을 때 Curriculum learning은 학습 난이도, 학습 시간을 줄이는 데에 효과적이고 특히 큰 factor에 효과적이다.
3.4.4 Multi-Supervision
- multi-supervision이란 기울기 전파 향상, 기울기 감소 방지, 기울기 폭주를 막기 위해 다수의 수퍼비전 시그널을 모델에 추가하는 것을 의미한다.
- "Supervision signals(지도 신호)"란 기계 학습 또는 딥러닝 모델에서 학습을 지도하는 데 사용되는 정보를 의미
- 재귀학습은 더 적은 파라미터로 향상된 표현을 학습할 수 있지만 여전히 높은 계산 비용을 피할 수 없다. 그리고 계속해서 소실되거나 넘치는 기울기 문제를 가져온다. 따라서, 재귀학습으로 인한 기울기 문제를 방지하기 위해 DRCN은 recursive unit과 multi-supervision을 통합한다.
- recursive unit의 각각 결과를 복원 모듈에 넣어 HR이미지를 생성한다 그리고 중간 복원을 모두 결합함으로써 최종 예측을 생성해낸다.
- MemNet에서도 recursive learning을 기반으로 한 비슷한 전략을 사용한다.
- progressive 업샘플링 프레임워크 하의 lapSRN은 전파 중에 다양한 규모의 중간 결과를 생성하기 때문에 multi-supervision 전략을 채택하는 것이 간단합니다.
- LapSRN(Laplacian Pyramid Super-Resolution) - coarse-to-fine 단계로 sub-band 잔차를 예측하는 특징 추출 경로와 두 경로의 신호를 기반으로 HR 이미지를 구성하는 또다른 경로를 포함한다.
- LapSRN의 중간 결과는 GT HR 이미지로부터 다운샘플된 이미지와 같도록 한다.
- Multi-supervision은 손실함수에 어떤 조건을 더함으로써 수행되고 이 방식에서는 supervision signals이 더욱 효과적으로 역전파된다 그래서 학습 난이도를 줄이고 모델 학습을 더욱 향상시킨다.
3.5 Other Improvements
3.5.1 Context-Wise Network Fusion(CNF)
- 여러 네트워크로부터 예측을 결합하는 stacking 기법을 말한다.( multi-path learning in section 3.3.3)
- 각각 다른 구조의 개별 SR 모델을 학습하고 각 모델의 예측을 개별 conv레이어에 넣은 후 최종적으로 결과를 합산하여 최종 예측이 된다.
- CNF framework를 포함한 최종 모델은 3개의 가벼운 SRCNN들로 구성된다. 이는 허용가능한 효율성으로 최신 기술과 대등한 성능을 달성한다.
3.5.2 Data Augmentation
- 딥러닝에서 성능 증진을 위해 가장 널리 사용되는 방식
- Image SR 에서 자르기, 뒤집기, 확대, 회전, 색상 변형 등의 증강 등이 있다.
- randomly shuffle RBG channels - 데이터 증강 뿐만 아니라 색상 불균형으로 유발되는 색상 편향을 완화한다.
3.5.3 Multi-Task Learning
- multi-task learning은 물체 감지, 의미 분할, 머리 자세 추정 및 얼굴 요소 추정 등 관련 작업의 훈련 시그널에 포함된 도메인별 정보를 활용하여 일반화 능력을 향상시킨다.
- "SFT-GAN,2016" 에서 의미론적 지식을 제공하고 의미론적 세부 정보를 생성하기 위해 의미론적 분할 네트워크를 통합한다.
- 픽셀에 대한 categorical prior를 정보를 통해 texture를 더 잘 잡아내는 것이 목표이다.
- spatial feature transform(SFT)을 통해서 feature map에 아핀 변환을 생성한다.
- 네트워크 내에 몇개의 레이어에 대해 SFT 레이어로 변형시켜 네트워크의 경향성을 임의대로 조정할 수 있다.
- 확장성 및 파라미터 감소 효과
- 효과, 많은 의미 영역에 사실적이고 시각적으로 만족스러운 텍스쳐를 생성한다.
- DNSR, 노이즈가 있는 이미지를 직접 초해상화하는 것은 노이즈 증폭을 유발. 따라서 노이즈 제거 네트워크와 SR 네트워크를 개별적으로 학습 후 이를 연결하여 fine-tune
- Cycle-in-cycle GAN
- Cycle-in-cycle 디노이징 프레임워크와 Cycle-in-cycle SR 모델을 결합해 노이즈 제거와 초해상도를 수행한다.
- 각각의 태스크들은 데이터의 다양한 측면에 중점을 두기 때문에 SR 모델을 관련작업과 결합하면 관련 작업에 대한 추가적인 정보와 지식을 제공해서 SR 성능을 향상시킨다(i.e, semantic + SR, denoising + SR)
3.5.4 Network Interpolation
- PSNR-based 모델은 GT와 더 가까운 이미지를 생성한다. 하지만 블러링 문제가 있다.
- GAN-based 모델은 지각 퀄리티가 더 좋지만 의미없는 노이즈가 이미지를 더욱 사실적으로 만들기 때문에 불만족스러운 결점이 있다.
- 형태적으로는 구현이 되지만 디테일에서 문제가 있음
- 왜곡과 인지 사이의 균형을 맞추기 위해 network interpolation 전략을 제안했다. (Esrgan, deep network interpolation)
- PSNR-based 모델을 학습하고 GAN-based 모델을 파인튜닝으로 학습한 다음 두 네트워크의 모든 파라미터를 보간하여 중간 모델을 도출한다.
- 네트워크의 재학습없이 가중치를 보간하여 튜닝하므로써 적은 결함과 의미 있는 결과물을 생성할 수 있다.
3.5.5 Self-Ensemble
- self-ensemble(a.k.a. enhanced prediction)은 주로 SR모델을 사용하는 추론 기술이다.
- 특히 0º, 90º,180º, 270º의 다양한 각도로 회전하고 접는 것으로 LR의 8개 이미지 세트를 얻을 수 있다.
- 그리고 이를 SR 모델에 넣고 뒤집힌 이미지들이 복원된 HR의 결과 생성에 적용된다.
- 최종 결과는 결과물의 평균이나 중간값으로 수행되어 더 나은 성능을 보인다.
3.5.6 State-of-the-Art Super-Resolution Models
- 앞서 SR 모델을 특정 요소로 분해해서 살펴봤다.
- 모델 프레임워크
- 업샘필링 방식
- 네트워크 디자인
- 학습 전략
- 이 요소들을 계층적으로 분석 및 한계점과 장점 파악
- 사실 최신 기술들은 이 모든 전략들의 조합으로 구성된다.
- 예를 들어, RCAN의 큰 기여는 channel attention에서부터 왔고 이것은 sub-pixel upsampling, residual learninb, pixel L1 loss, self-ensemble 등에서 적용됐다.

Deep Learning for Image Super-Resolution: A Survey(2) (2021.10)
Deep Learning for Image Super-Resolution: A Survey(1) (2021.10)
Deep Learning for Image Super-Resolution: A Survey (2021.10) IEEE, 1400회 인용, 23p 🎈목차 기존 연구 class methods deep-learning based methods SR 문제 정의 유명 데이터셋 성능 평가 지표, IQA PSNR, SSIM, MOS, Learning-based Percept
2ndyoung.tistory.com
참고
영상처리 주파수
영상 처리/컴퓨터 비전 - 주파수 영역과 공간 주파수(Spatial Frequency)
[Computer Vision-03] Image Pyramid
Wavelet Transform 기본개념 및 Fourier Transform 비교
[비전5] Frequency and Image
[논문 리뷰] SPPNet(2014) 설명 (Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition)
[웨이블릿 이해하기] Wavelet 이란?
[논문 리뷰] SFT-GAN : Spatial Feature Transform
'논문' 카테고리의 다른 글
| Image and video upscaling from local self-examples(2011.04) (1) (0) | 2024.03.02 |
|---|---|
| Deep Learning for Image Super-Resolution: A Survey(3) (2021.10) (0) | 2024.02.15 |
| Deep Learning for Image Super-Resolution: A Survey(1) (2021.10) (0) | 2024.01.31 |
| A Survey of Large Language Models(2023.03) (0) | 2024.01.19 |
| Deep Neural Networks for YouTube Recommendations(2016.09) (0) | 2024.01.09 |


