
Bamboo is coming
[랩세미나]Anomaly Detection in Surveillance Video 본문
http://dmqa.korea.ac.kr/activity/seminar/413
고려대학교 DMQA 연구실
고려대학교 산업경영공학부 데이터마이닝 및 품질애널리틱스 연구실
dmqa.korea.ac.kr
video anomaly dectection의 종류
1. fully supervised
이상이 발견된 프레임에 labeling
2. weakly supervised
이상이 발견된 동영상에 labeling
3. unsupervised
labeling 생략, 정상적인 frame이 더 많고 이상적인 현상이 더 적게 발생한다는 가정하에 학습
Real-world Anomaly Dectection in Survelilance Video(IEEE, 2018)
인용수 1200회 가량
문제점
정상과 비정상의 경계 모호 (이상치 탐지에 관한 문제점)
모든 이상현상 나열 불가 (이상치 탐지에 관한 문제점)
시간대별로 급격히 변화(비디오 문제점?
제안 방식
supervision 최소화 - > weakly labeled training video 사용
2018년 해당 연구 이전에는 frame별 label이었으나 본 논문에서는 video별 label 제시
기여점
MIL(multiple instance learning)을 사용하여 weakly labeled training video로 이상탐지
SOTA 대비 좋은 성능
가공되지 않은 video 데이터를 사용한 연구
MIL(multiple instance learning)이란 Instance 각각에 Label이 붙어 그것을 예측하는 것이 아니라 여러개의 Instance가 bag을 이루고 이 bag에 Label이 붙어 그것을 예측하는 것을 말한다.
Weakly Supervised라고도 하며 예시로는 어떤 포도의 포도알 각각의 사진을 모아놓은 bag이 있다고 할 때 포도알이 하나라도 상한 포도알이라면 collection 전체를 상한 포도로 분류하는 것을 의미한다.
제안 방법
MIL(multiple instance learning)
anomaly video와 normal video 사용
프레임 모음을 instance라고 하고 positive bag, negative bag으로 나뉜다.
C3D feature extractor를 통해 feature -> segment별 anomaly score 계산
Deep MIL Ranking Model
SVM loss 활용 -> anomaly bag의 score는 커져야하고 normal bag의 score는 작아져야 한다.
1. add smootheness constrain in loss function
실험
비교 대상
Lu et al : dictionary 기반 접근 재구축 오차 감지,
Hasanet et al : deep auto Encoder
동물을 확대함에 따라 anomaly score 증가
Self-Training Multi-sequence Learning with Transfomer for weakly supervosed video anomaly detection(AAAI, 2023)
문제점
MIL 방법론의 문제
- 정상 instance가 비정상 instance로 예측되면 후속 instance 선택시 오류 증가
- 비정상 이벤트는 여러개 instance의 집합이지만 MIL은 고려 X
제안
MSL(Multi-sequence learning)
instance 1개만을 손실함수로 계산하는 것이 아니라 여러 instance로 구성된 sequence를 최적화의 단위로 사용.
MSL에서는 이상 점수의 합계가 가장 높은 sequence를 선택 및 학습에 활용
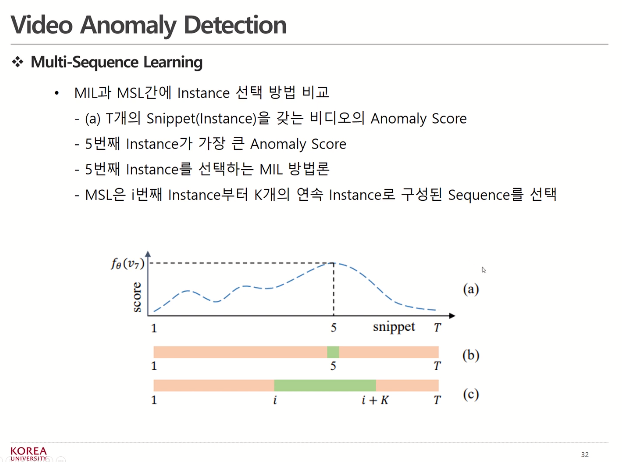
MIL : anomaly score가 가장 높은 5번
MSL : 5번 주위에 있는 hyperparameter인 k개를 선택 -> anomaly score의 평균이 가장 큰 sequence 선택
구조
backnone(C3D, I3D, VideoSwin + pre-trained W)에서 특징 추출
추출된 특징과 class token을 CTE(convolution transformer encoder) 입력
feture는 regressor로 입력하여 instance별 anomaly score 산출 -> MSL ranking loss
class token은 classifier를 통과하여 확률값 산출 BCE(Binary cross entropy) loss 계산
여기서 확률값은 영상 전체에 대한 분포를 이야기하며 이상치 감지 내용을 찾아냄
MSL ranking loss는 sequence별로 계산
loss는 classifier, ranking loss를 모두 포함한 손실임
anomaly score의 변동을 줄이기 위해 score correction 방법을 사용하는데
anomaly가 있을 확률을 곱하는 방식으로 score를 보정하고 있음
Self-training
초기 학습시는 잘못된 sequence 선택으로 예측 성능이 매우 낮음
weakly supervised기 때문에 동영상에 부여된 label을 pseudo label로 활용하고 pseudo label로 sequence를 선택후 학습
예측하 값으로 시퀀트를 선택하여 학습하고 + 수도 레이블을 업데이트하며 정확도를 향상 시킴
결과
전체적으로 AUC가 높은 것을 확인할 수 있음

'논문' 카테고리의 다른 글
| Deep Neural Networks for YouTube Recommendations(2016.09) (0) | 2024.01.09 |
|---|---|
| [랩세미나]XAI (0) | 2023.11.29 |
| stable diffusion for developers (0) | 2023.10.13 |
| Video Diffusion Study (0) | 2023.10.09 |
| Score-based Generative Models and Diffusion Models (0) | 2023.09.07 |



