
Bamboo is coming
Video Diffusion Study 본문
2022년에 Google Research에서 발표한 Imagen video: High definition video generation with diffusion models
(논문, https://arxiv.org/abs/2210.02303)
2023년 기준 총 309회의 인용으로 2022년 10월 발표 이후 활발하게 연구가 진행되고 있다.
기존에 Text-to-image 모델인 Imagen을 비디오 형태로 제안했다. 최초의 비디오 diffusion 모델을 제시한다고 저자는 언급하고 있다.
현재 연구는 image에서 SOTA를 달성한 모델을 영상으로 확장 적용하는 형태로 진행되고 있음.
논문 리뷰 VideoCLIP: Contrastive Pre-training for Zero-shot Video-Text Understanding (https://www.thedatahunt.com/tech-review/contrastive-pre-training-for-zero-shot-video-text-understanding)
text to image 모델인 CLIP을 text to video 형태로 학습시킴
논문 리뷰 Tune-A-Video :One-Shot Tuning of Image Diffusion Models for Text-to-Video Generation (https://kyujinpy.tistory.com/98)
text to image 모델인 diffusion의 파인튜닝 text to video
https://paperswithcode.com/task/video-generation/latest
Papers with Code - Video Generation
<span style="color:grey; opacity: 0.6">( Various Video Generation Tasks. Gif credit: [MaGViT](https://paperswithcode.com/paper/magvit-masked-generative-video-transformer) )</span>
paperswithcode.com
VideoFusion: Decomposed Diffusion Models for High-Quality Video Generation
https://kimjy99.github.io/%EB%85%BC%EB%AC%B8%EB%A6%AC%EB%B7%B0/videofusion/
VideoFusion의 자료 사진을 보면 noised latent 변수가 생성한 사진에서 noise를 공유하냐 하지 않냐에 따라서 동일한 시퀀스를 합성할 수 있다. 이는 동영상 생성 DPM의 denoising network 부담을 경감할 수 있다고 한다. 그 외에도 기본 noise가 모든 프레임에서 공유되므로 한번의 forward pass로 공급하여 예측할 수 있다.
중요 기여
1. denoising process의 편리를 위해 연속 프레임 간의 유사성 활용 -> diffusion process 분리
프레임을 기본 프레임과 나머지의 두 부분으로 분리
noised latent에서 추가된 노이즈 역시 base noise와 residual noise로 분리
따라서 x의 noised latent 변수 z는 동영상 프레임의 공통 부분 \(x^0\)의 디퓨전과 나머지 의 디퓨전 두 부분으로 나눈다.
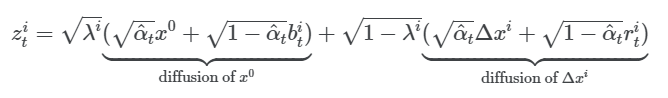
이전 방법에서 공유되는 \(x^0\)으로 denoising을 수행했으나 현재 수식에서는 각 프레임에서 서로 다른 값으로 독립적인 noise가 발생하므로 denoising의 어려움이 있을 수 있다. 따라서 base noise를 공유하여 다른 프레임의 \(x^0\)에서 동일한 값으로 noise되도록 했다.
b가 공유되면서 인접한 diffusion step 사이에도 분해된 형태가 유지된다.
프레임의 공통부분 \(x^0\)와
동영상 프레임 간의 유사성을 활용하기 위해 프레임 \(를 기본 프레임 \(x^0\) 와 나머지 의 두 부분으로 나눈다.
\[x^i=\sqrt{\lambda^i}x^0+\sqrt{1-\lambda^i}\Delta x^i, i=1,2,...N \]
여기서 \(x^0\) 은 동영상 프레임의 공통 부분을 나타내고 \( \lambda^i\) 는 \(x^i\) 에서 \(x^0\) 의 비율을 나타낸다. 특히, \(\lambda^i=0\) 은 \(x^i\) 가 \(x^0\) 와 공통점이 없음을 나타내고, \(\lambda^i=1\) 은 \(x^0=0\) 을 나타낸다. 이와 같이 동영상 프레임 간의 유사도는 \(x^0\) 와 \(\lambda^i\) 를 통해 파악할 수 있다.
2
'논문' 카테고리의 다른 글
| [랩세미나]Anomaly Detection in Surveillance Video (1) | 2023.10.26 |
|---|---|
| stable diffusion for developers (0) | 2023.10.13 |
| Score-based Generative Models and Diffusion Models (0) | 2023.09.07 |
| Diffusion Model(Denoising Diffusion Probabilistic Models, DDPM), 디퓨전 모델 (0) | 2023.09.07 |
| (논문)GAN(Generative Adversarial Network) (0) | 2023.09.05 |

