
Bamboo is coming
Grad-CAM, 코드 구현 및 수식 설명 (pytorch) 본문
논문 VIsual Explanation from Depp Networks via Gradient based Localization, Grad-CAM, 2017 CVPR
Grad-CAM(Gradient-weighted Class Activation Mapping)
XAI를 구현할 수 있는 시각적 설명 방법, class-discriminative localization technique
Convolutional Neural Network (CNN) 기반의 모델이 만든 의사결정에 대한 'visual explanations'를 만드는 기술을 제안하며, 이는 CNN 기반의 모델을 더욱 투명하고 설명 가능하게 만듭니다.
(Grad-CAM)은 final convolutional layer로 흐르는 target concept의 gradient를 사용해서 concept을 예측할 때 이미지에서 중요한 부분들을 강조하는 coarse localization map을 만들어냅니다.
** target concept - (classification network에서는 'dog'가 될 수 있으며, captioning network에서는 word의 sequence가 될 수 있습니다.)
장점
- failure mode에 대한 insight를 제공합니다. (비합리적으로 보이는 예측이 합리적인 설명을 가지고 있다는 것을 입증합니다.)
- ILSVRC-15 weakly-supervised localization task에 대해서 이전 method에 비해 더 좋은 성능을 냅니다.
- adversarial perturbation에 강건합니다.
- underlying model에 대해 더욱 믿음을 가질 수 있게 해 줍니다.
- dataset bias를 확인함으로써 model generalization를 성취하는데 도움을 줍니다.
Grad-CAM의 발전
- CAM
Zhou et al. 은 discriminative regions을 식별하고자 fully-connected layer가 없는 image classification CNN에 사용되는 기법인 Class Activation Map을 제안하였습니다.
본질적으로, CAM은 모델의 작동에 대한 투명성을 높이고자 모델의 복잡성과 성능을 절충하게 됩니다.
(Fully-connected layer를 제거하므로 parameter의 수가 줄어들게 되고 이에 따라 성능도 줄어들기 때문이죠.) - Grad-CAM -
Guided Back-propagation과 Deconvolution와 같은 pixel-space gradient visualization은 high-resolution이고 이미지 내에서 fine-grained detail을 강조하지만, class-discriminative 하지는 않습니다. (Fig. 1b와 Fig. 1h가 매우 유사한 것이 그 예시가 됩니다.)
그에 반해서, CAM이나 저자들이 제안하는 방법인 Gradient-weighted Class Activation Mapping (Grad-CAM)와 같은 localization approaches는 매우 class-discriminative 합니다. ('cat'에 대한 설명은 오로지 'cat' region만 강조하며 'dog' region을 강조하지 않습니다. Fig. 1c, Fig. 1i을 통해 확인할 수 있습니다.)
두 방법론의 장점을 결합하기 위해, 저자들은 high-resolution이고 class-discriminative 한 Guided Grad-CAM visualization을 만들어 내기 위해 pixel-space gradient visualization을 Grad-CAM과 결합하는 것이 가능하다는 것을 보입니다. - Guided Grad-CAM explanation
Guided Grad-CAM is an extension that combines Grad-CAM with Guided Backpropagation.
XAI에 대한 더 자세한 내용은 Explainable AI(XAI) 참고

Grad-CAM을 사용하려면 일반적으로 완전히 연결된 레이어 전에 최종 컨볼루션 레이어를 대상으로 합니다. 이 레이어에는 모델이 학습한 풍부한 기능 정보가 포함되어 있기 때문입니다.
VGG16의 경우 마지막 컨볼루션 레이어를 선택할 수 있는데, 일반적으로 다섯 번째 블록의 세 번째 컨볼루션 레이어(즉, 'conv5_3')입니다. 이 선택을 통해 Grad-CAM은 모델의 결정에 기여한 이미지의 중요한 영역을 시각화할 수 있습니다.
○ Grad-CAM(Gradient Class Activation Map)
논문 VIsual Explanation from Depp Networks via Gradient based Localization, Grad-CAM, 2017 CVPR
Grad-Cam은 CAM의 단점을 보완하고 발전한 알고리즘이다. CAM은 FC layer 대신에 GAP를 써야만 했기 때문에 모델의 구조를 바꿔야만 하는 단점이 있었다. Grad-CAM은 GAP(Global Average Pooling)로 FC layer를 만들고 feature map channel에 대한 weight를 직접 구하는 대신에, 모델 구조는 그대로 두고 feature map channel에 대한 gradient를 구해서 channel별 가중치를 구한다.
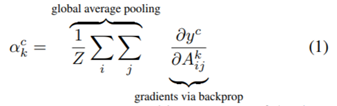
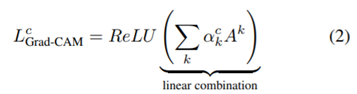
(1) 마지막 convolution layer를 통과한 feature map을 {A^{k} \in R^{\mu \times v }} (A:feature map, k:feature, u:width, v:height) 이라고 하고 summation으로 GAP한 것과 같은 값을 구할 수 있다. 모델이 분류했을 때 예측한 확률 값을 y로 하고 feature map {A^k} 에 대하여 미분하면 {A^k}의 가중치를 알 수 있다.
(2) 가중치가 음수일 경우는 모델이 최종 예측한 class가 아닌 다른 class라고 예측하는데 중요한 정보임을 의미한다. 다른 class를 예측하는데 중요한 정보에는 관심이 없으므로 기울기가 양수일 때만 시각화할 수 있도록 ReLU를 이용해서 Class Activation Map을 완성한다.

위는 Visual Question Answering에 Grad-CAM을 적용한 결과이다. CAM과 마찬가지로 모델이 예측할때 집중한 부분을 heatmap 형식으로 시각화한다.
함수 설명
torch.autograd
torch.autograd.save_for_backward
Global Average Pooling
Grad-CAM pytorch 소스 코드
# 함수로만 구현
import torch
import torch.nn.functional as F
import numpy as np
import cv2
def generate_grad_cam(img_tensor, model, target_class, target_layer):
"""
img_tensor: PyTorch tensor, 이미지 전처리를 거친 tensor
model: pretrained model (예: resnet50 등)
target_class: 원하는 클래스의 인덱스
target_layer: 시각화하려는 레이어 (예: model.layer4[2].conv3)
return:
grad_cam: grad_cam 히트맵
"""
# gradient 정보를 저장하는 hook을 정의합니다.
gradients = []
activations = []
def backward_hook(module, grad_input, grad_output):
gradients.append(grad_output[0])
def forward_hook(module, input, output):
activations.append(output)
# 원하는 계층에 hook을 추가합니다.
hooks = []
hooks.append(target_layer.register_backward_hook(backward_hook))
hooks.append(target_layer.register_forward_hook(forward_hook))
# forward pass
outputs = model(img_tensor)
# 원하는 클래스에 대한 출력을 가져와서 backward pass를 수행합니다.
output = outputs[0, target_class]
model.zero_grad()
output.backward()
# hook을 제거합니다.
for hook in hooks:
hook.remove()
# 원하는 계층의 출력과 gradient를 가져옵니다.
gradient = gradients[0]
activation = activations[0]
pooled_gradient = torch.mean(gradient, dim=[2, 3])
for i in range(pooled_gradient.shape[1]):
activation[:, i, :, :] *= pooled_gradient[0][i]
# heatmap을 생성합니다.
grad_cam = torch.mean(activation, dim=1).squeeze().detach().cpu().numpy()
grad_cam = cv2.resize(grad_cam, (224, 224))
grad_cam = np.maximum(grad_cam, 0)
grad_cam /= grad_cam.max()
return grad_cam
이 함수는 주어진 이미지, 모델, 타겟 클래스, 그리고 원하는 계층을 기반으로 Grad-CAM 히트맵을 생성합니다. img_tensor는 이미 전처리된 상태의 이미지 텐서, model은 사전 훈련된 모델, target_class는 원하는 클래스의 인덱스, 그리고 target_layer는 시각화하고자 하는 계층입니다.
# 클래스로 구현
import torch
import torch.nn.functional as F
import torchvision.models as models
import torchvision.transforms as transforms
import numpy as np
import cv2
import matplotlib.pyplot as plt
from PIL import Image
class GradCAM:
def __init__(self, model, target_layer):
self.model = model
self.target_layer = target_layer
self.gradients = None
self.model.eval()
self.hook_layers()
def hook_layers(self):
def hook_function(module, grad_in, grad_out):
self.gradients = grad_in[0]
self.target_layer.register_backward_hook(hook_function)
def generate_cam(self, input_image, target_class):
model_output = self.model(input_image)
one_hot_output = torch.zeros((1, model_output.size()[-1]), device=input_image.device)
one_hot_output[0][target_class] = 1
self.model.zero_grad()
model_output.backward(gradient=one_hot_output)
activations = self.model.features(input_image).detach()
pooled_gradients = torch.mean(self.gradients, dim=[0, 2, 3])
for i in range(activations.shape[1]):
activations[:, i, :, :] *= pooled_gradients[i]
heatmap = torch.mean(activations, dim=1).squeeze().cpu().numpy()
heatmap = np.maximum(heatmap, 0)
heatmap /= heatmap.max()
return heatmap
img_path = "cats_and_dogs_small/train/cats/cat.0.jpg"
img = Image.open(img_path)
preprocess = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
input_image = preprocess(img).unsqueeze(0).cuda()
model = models.vgg16(pretrained=True).cuda()
target_class = 0 # 예: 웰시코기 클래스(243)를 대상으로 함
grad_cam = GradCAM(model, model.features[29])
heatmap = grad_cam.generate_cam(input_image, target_class)
img = cv2.imread(img_path)
heatmap_resized = cv2.resize(heatmap, (img.shape[1], img.shape[0]))
heatmap_resized = np.uint8(255 * heatmap_resized)
heatmap_colored = cv2.applyColorMap(heatmap_resized, cv2.COLORMAP_JET)
superimposed_img = heatmap_colored * 0.4 + img
plt.imshow(cv2.cvtColor(superimposed_img.astype(np.uint8), cv2.COLOR_BGR2RGB))
plt.axis('off')
plt.show()Grad-CAM을 구현하는 방식에는 여러 가지 접근법이 있지만, 대부분의 접근법은 다음 두 가지 주요 구성 요소를 사용합니다:
1. Target Layer의 활성화 (Activations)
2. 해당 활성화에 대한 그래디언트 (Gradients)
이 두 가지 정보를 기반으로 Grad-CAM 히트맵을 계산합니다.
다음은 Grad-CAM을 구현하는 주요 방법들입니다:
1. Hook을 사용하는 방법: 여기서는 forward와 backward hook을 사용하여 중간 계층의 활성화 및 그래디언트를 캡처합니다. 이 방식의 주요 장점은 모델의 중간 계층에 직접 액세스하지 않고도 필요한 정보를 얻을 수 있다는 것입니다.
2. Grad-CAM 클래스: 이 방식은 클래스를 사용하여 모든 구성 요소와 계산을 캡슐화합니다. 이 방식의 장점은 재사용성과 코드의 명확성입니다. 사용자는 클래스 인스턴스를 생성하고 필요한 메서드를 호출하여 Grad-CAM을 얻을 수 있습니다.
3. 직접 계산하는 방법: 여기서는 모델의 내부 계층에 직접 액세스하여 필요한 활성화와 그래디언트를 얻습니다. 이 방식은 코드가 간결하고 명확하지만, 모델의 내부 구조에 대한 지식이 필요합니다.
일반적으로, 가장 자주 사용되는 방식은 Hook을 사용하는 방법과 Grad-CAM 클래스를 사용하는 방법입니다. 이 두 방식은 코드의 명확성과 재사용성 측면에서 유용합니다. 선택한 방식은 구현하려는 문제의 복잡성, 코드의 명확성 및 재사용 요구 사항에 따라 달라질 수 있습니다.
함수 기반 vs. 클래스 기반 Grad-CAM의 차이점과 장단점:
재사용성:
클래스 기반: 클래스의 인스턴스를 한 번 생성하면 여러 이미지에 대해 Grad-CAM을 생성할 때 동일한 인스턴스를 재사용할 수 있습니다.
함수 기반: 각 이미지에 대해 함수를 호출할 때마다 필요한 모든 내용을 전달해야 합니다.
구조 및 가독성:
클래스 기반: 클래스의 구조는 코드의 조직화와 재사용성을 높일 수 있습니다. 모든 관련 함수와 변수가 클래스 내에 있기 때문에 관리하기가 더 쉽습니다.
함수 기반: 함수는 일반적으로 단순한 작업에 더 적합하며 빠르게 결과를 얻을 수 있습니다. 그러나 복잡한 작업에는 클래스가 더 적합할 수 있습니다.
유연성:
클래스 기반: 클래스는 메서드 오버라이드와 같은 객체 지향 기능을 활용하여 확장성과 유연성을 높일 수 있습니다.
함수 기반: 함수는 일반적으로 더 간단하며 특정 작업에 초점을 맞추도록 설계되었습니다.
메모리 사용:
클래스 기반: 클래스 인스턴스는 자체 상태와 변수를 유지하기 때문에 메모리 사용량이 더 클 수 있습니다.
함수 기반: 함수는 일반적으로 호출될 때만 메모리를 사용하고 반환 후 메모리를 해제합니다.
결론적으로, 함수 기반과 클래스 기반 접근 방식 사이의 선택은 특정 작업과 개인의 코딩 스타일에 따라 달라질 수 있습니다. 클래스 기반 접근 방식은 재사용성과 확장성이 높지만, 함수 기반 접근 방식은 간결하고 특정 작업에 더 집중적일 수 있습니다.
import torch
import torch.nn as nn
import torch.nn.functional as F
from google.colab.patches import cv2_imshow
class GradCam(nn.Module):
def __init__(self, model, module, layer):
super().__init__()
self.model = model
self.module = module
self.layer = layer
self.register_hooks()
def register_hooks(self):
for modue_name, module in self.model._modules.items():
if modue_name == self.module:
for layer_name, module in module._modules.items():
if layer_name == self.layer:
module.register_forward_hook(self.forward_hook)
module.register_backward_hook(self.backward_hook)
def forward(self, input, target_index):
outs = self.model(input)
outs = outs.squeeze() # [1, num_classes] --> [num_classes]
# 가장 큰 값을 가지는 것을 target index 로 사용
if target_index is None:
target_index = outs.argmax()
outs[target_index].backward(retain_graph=True)
a_k = torch.mean(self.backward_result, dim=(1, 2), keepdim=True) # [512, 1, 1]
out = torch.sum(a_k * self.forward_result, dim=0).cpu() # [512, 7, 7] * [512, 1, 1]
out = torch.relu(out) / torch.max(out) # 음수를 없애고, 0 ~ 1 로 scaling # [7, 7]
out = F.upsample_bilinear(out.unsqueeze(0).unsqueeze(0), [224, 224]) # 4D로 바꿈
return out.cpu().detach().squeeze().numpy()
def forward_hook(self, _, input, output):
self.forward_result = torch.squeeze(output)
def backward_hook(self, _, grad_input, grad_output):
self.backward_result = torch.squeeze(grad_output[0])
if __name__ == '__main__':
def preprocess_image(img):
means = [0.485, 0.456, 0.406]
stds = [0.229, 0.224, 0.225]
preprocessed_img = img.copy()[:, :, ::-1]
for i in range(3):
preprocessed_img[:, :, i] = preprocessed_img[:, :, i] - means[i]
preprocessed_img[:, :, i] = preprocessed_img[:, :, i] / stds[i]
preprocessed_img = \
np.ascontiguousarray(np.transpose(preprocessed_img, (2, 0, 1)))
preprocessed_img = torch.from_numpy(preprocessed_img)
preprocessed_img.unsqueeze_(0)
input = preprocessed_img.requires_grad_(True)
return input
def show_cam_on_image(img, mask):
# mask = (np.max(mask) - np.min(mask)) / (mask - np.min(mask))
heatmap = cv2.applyColorMap(np.uint8(255 * mask), cv2.COLORMAP_JET)
heatmap = np.float32(heatmap) / 255
cam = heatmap + np.float32(img)
cam = cam / np.max(cam)
cv2_imshow(np.uint8(255 * cam))
cv2_imshow(np.uint8(heatmap * 255))
cv2.waitKey()
import os
import cv2
import glob
import numpy as np
from torchvision.models import vgg16
model = vgg16(pretrained=True)
# print(model)
model.eval()
grad_cam = GradCam(model=model, module='features', layer='30')
img_path = "cats_and_dogs_small/train/cats/cat.20.jpg"
img = cv2.imread(img_path, 1)
img = np.float32(cv2.resize(img, (224, 224))) / 255
input = preprocess_image(img)
mask = grad_cam(input, None)
show_cam_on_image(img, mask)

VGG16으로 하는 grad-cam이 backward hook이 안 먹는다..
-> 기존 코드에서 layer를 인식을 못해서 backward의 gradients가 계속 None으로 나왔는데 vgg16에서는 같은 conv 연산을 여러번 하기 때문이어서인지 레이어를 지정하는 것이 아니라 순회하면서 모든 레이어와 대조하면서 일치하는 레이어를 찾아서 hook를 등록해줬더니 드디어 backward 연산이 먹혔다. 그리고 기존에는 layer를 layer.feature[-1]로 했는데 layer를 '30'으로 지정해줬더니 잘 먹힌다. 배워도 배워도 배울게 계속 생기는게 신기하기만 하다.
결국 논문을 이해해야 코드도 이해할 수 있다는 것을 배웠다..ㅎ
참고
논문 VIsual Explanation from Depp Networks via Gradient based Localization, Grad-CAM, 2017 CVPR
Grad-CAM 논문 리뷰
Grad-CAM 코드 리뷰 pytorch + Resnet (상세한 주석)
Grad-CAM 코드 pytorch + Resnet
Grad-CAM pytorch 소스 코드 + Resnet + VGG (상세한 모델 설명)
CAM 설명
'논문' 카테고리의 다른 글
| Score-based Generative Models and Diffusion Models (0) | 2023.09.07 |
|---|---|
| Diffusion Model(Denoising Diffusion Probabilistic Models, DDPM), 디퓨전 모델 (0) | 2023.09.07 |
| (논문)GAN(Generative Adversarial Network) (0) | 2023.09.05 |
| Guided Grad-CAM (0) | 2023.08.10 |
| VGG16 논문 리뷰 (0) | 2023.08.10 |
